
Es difícil pensar que hubo alguna vez un momento en el que le hayamos prestado tanta atención como ahora al modelado epidemiológico, a la visualización de datos, a lo que significa tomar una muestra poblacional o tratar de entender cada uno de los saltos que existen entre los modelos, sus simplificaciones y la realidad.
Según estimaciones de la Universidad de Internet, a partir del 4 de abril toda conversación será solamente sobre exponencialidad, convirtiéndose en nuestro último y supremo meme.
Tanta es la conversación y tan diversos los interlocutores válidos para construirla de manera que aporte a la toma de decisiones, que decidimos tratar de compartir lo que sabemos y no sabemos de los modelos, explicitar sus limitaciones y posibilidades, hacer especial hincapié en cuáles son los supuestos sobre los que operan y entender cómo las acciones concretas podrían afectar distintos aspectos del progreso epidemiológico, eso que hoy ya todos conocemos como ‘la forma de la curva’.
Curva que, hasta estos días, pensamos en su forma más sencilla: la exponencial. Esos procesos que crecen todos los días de manera proporcional al día anterior, una y otra vez. Procesos de los que hemos hablado tal vez 1, 2, 4, 8 o hasta 16 veces, y sobre las que está muy orientada esta nota anterior.
Introducción a la Introducción de Modelado de Epidemias
Hablar de modelado de epidemiología (saltando, por el amor de Thor, la exponencialidad), es hablar del modelo SIR, que imagina 3 tipos de estado para cada agente (persona) involucrado en el desarrollo de la epidemia. S viene de Susceptible, I de Infectado y R de Removido (o Recuperado, pero capaz mejor Removido que puede implicar que se recuperó o que murió).
Este es el modelo más simple y tiene un montón de supuestos, el primero y tal vez más importante es la unidireccionalidad: la persona pasa de Suceptible a Infectada y de Infectada a Removida. Nunca en sentido contrario. Esos cambios de estado los gobiernan distintos factores. El paso de S a I es afectado por: el número de contactos que cada persona tiene con otra, el estado y proporción de personas en distintos estados en la población (no es lo mismo salir a la calle y encontrarte a un Infectado que a un Susceptible, y esa probabilidad cambia a medida que progresa el desarrollo de la infección), y la probabilidad de que esa interacción resulte en una infección. El paso de I a R depende del tiempo que transcurre entre que una persona es infectada y es −ejem− removida.

Y la forma clásica y básica de esa curva es esta:
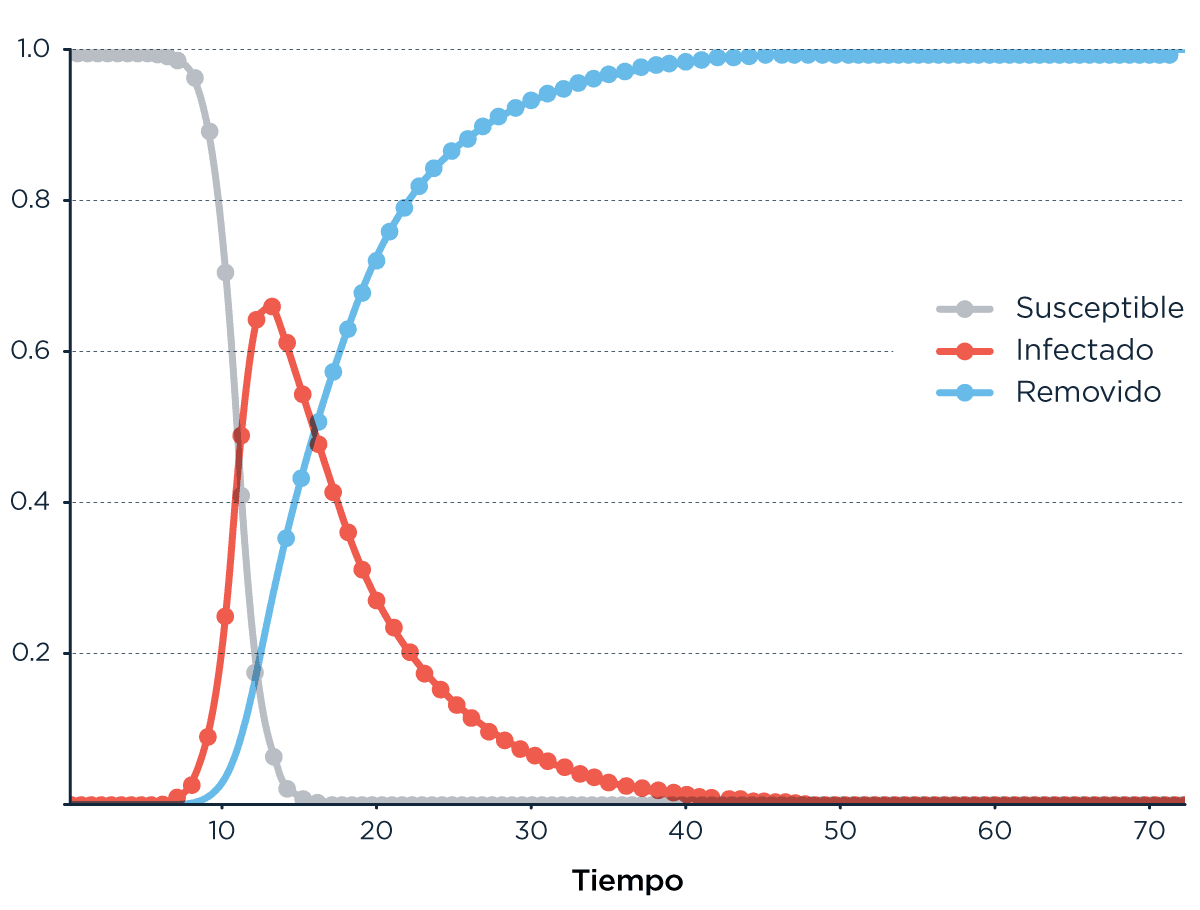
La altura del pico, el ancho de la curva, su área o cuánto tiempo demora hasta empezar a subir abruptamente son el resultado de cómo sean esos parámetros que gobiernan los cambios entre un estado y el otro.
Esa aceleradita inicial en los Infectados arranca de manera que se parece muchísimo a una exponencial. A ESA exponencial de la que venimos oyendo, un modelo que se aproxima bien a lo que quiere representar, apenas un tiempo, solamente bien al principio, y cuando la curva empieza a desacelerarse empieza a dejar de ajustar, y la realidad a despegarse del modelo exponencial (momento que nos tiene cruzados de dedos a los más agnósticos).
Primeras vacas esféricas
En física se suele hacer siempre el mismo chiste, un ejercicio teórico utilizando vacas, pero dando por sentado para facilitar los cálculos que son vacas ideales, o sea perfectamente esféricas y sin rozamiento. Bueno, en nuestro caso, una de las primeras vacas esféricas a conversar es esa idea de que una persona transmite la enfermedad, en promedio, a un número determinado de otras personas. Este valor (R0) es distinto (y característico) para distintas enfermedades: el sarampión tiene R0 estimado de entre 12 y 18 (se transmite por aire), la rubeola 5 a 7 (se transmite por microgotas), y el COVID19 (también por microgotas) de entre 1.4 y 3.9.
Todos estos valores de R0 son apenas informativos, porque lo que interesa a la hora de hacer un modelado no es el número teórico de personas que se infectan, sino un número concreto en un momento y condiciones determinadas que están dadas por múltiples factores (al que llamamos R). Las diferentes intervenciones que hoy se aplican son, precisamente, para tratar de bajar ese R.
Lo que sí es clave y es una frontera es el 1. Si el valor de R está por encima de 1, la enfermedad se está expandiendo (la situación es epidémica). Si está en 1, es que la enfermedad permanece en territorio sin expandirse pero presente (decimos que es endémica). Si está por debajo de 1, se está controlando.
Uno de los desafíos más grandes en este momento (el que tiene múltiples equipos en todo el mundo trabajando contra reloj) es tratar de entender cómo distintos tipos de intervención cambian ese R. Hace apenas unos días salió un trabajo de Imperial College donde evalúan precisamente eso: recopilando datos sobre la forma en la que se tomaron medidas en diferentes países, tratan de hacer la inferencia sobre cuán efectivas son a la hora de cambiar esa tasa de reproducción y, al final, qué impacto tienen en el progreso potencial de la epidemia.
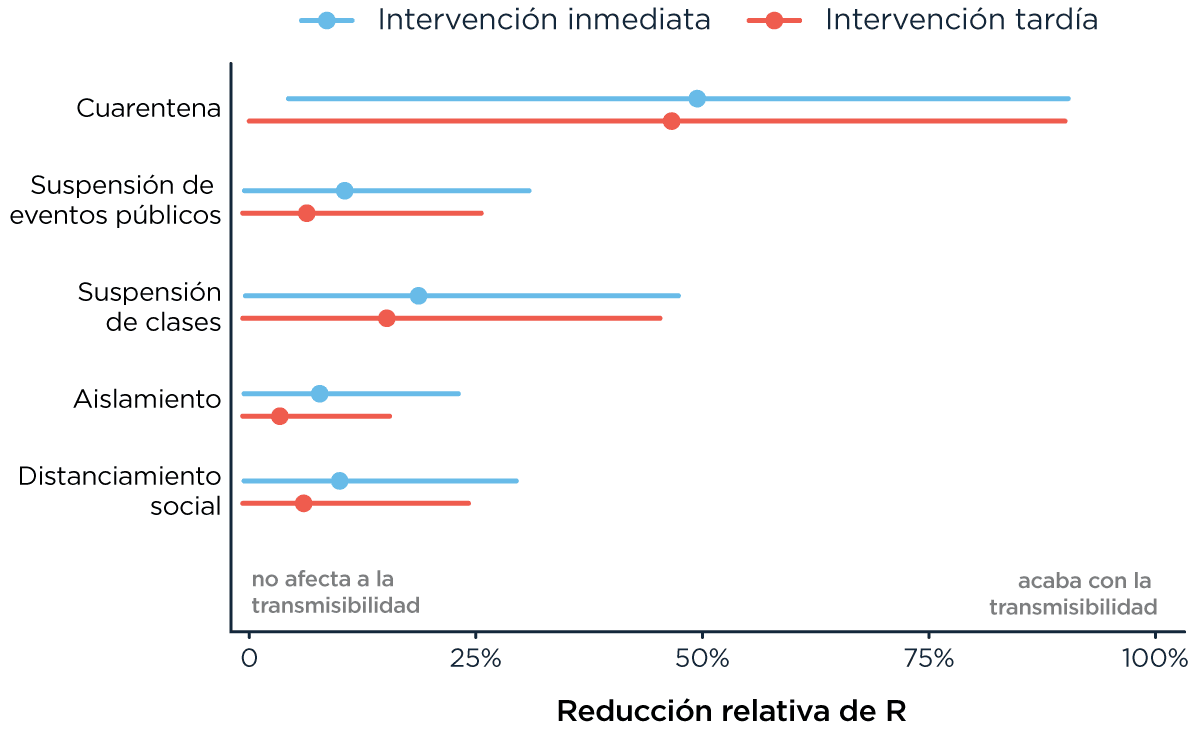
Reducción relativa de R en % para cada tipo de intervención estatal. Cada uno es, en teoría, acumulativo. Una dificultad del estudio radicó en que en muchas ocasiones fueron tomadas varias medidas al mismo tiempo y eso dificulta asignarles importancia por separado. Las líneas indican el intervalo de confianza. Esos intervalos de confianza me generan poca confianza. (Estrictamente, me dan bastante seguridad porque entiendo cuánto estiman que saben y me lo dicen explícitamente, pero como juego de palabras es muchísimo más largo).
Lo primero a observar es la incertidumbre: sabemos muy poco y hacer modelados es muy difícil, entre otro montón de cosas, por la falta de datos y la diversidad en la que esos datos son tomados. Este equipo, para construir sus modelos, usó como dato principal el número de muertos, no diagnósticos, porque asumió que era una métrica más robusta.
Usando ese R para distintos tiempos, y armando ‘etapas’ que corresponden a cada intervención, el progreso de Italia, por ejemplo, se ve así:
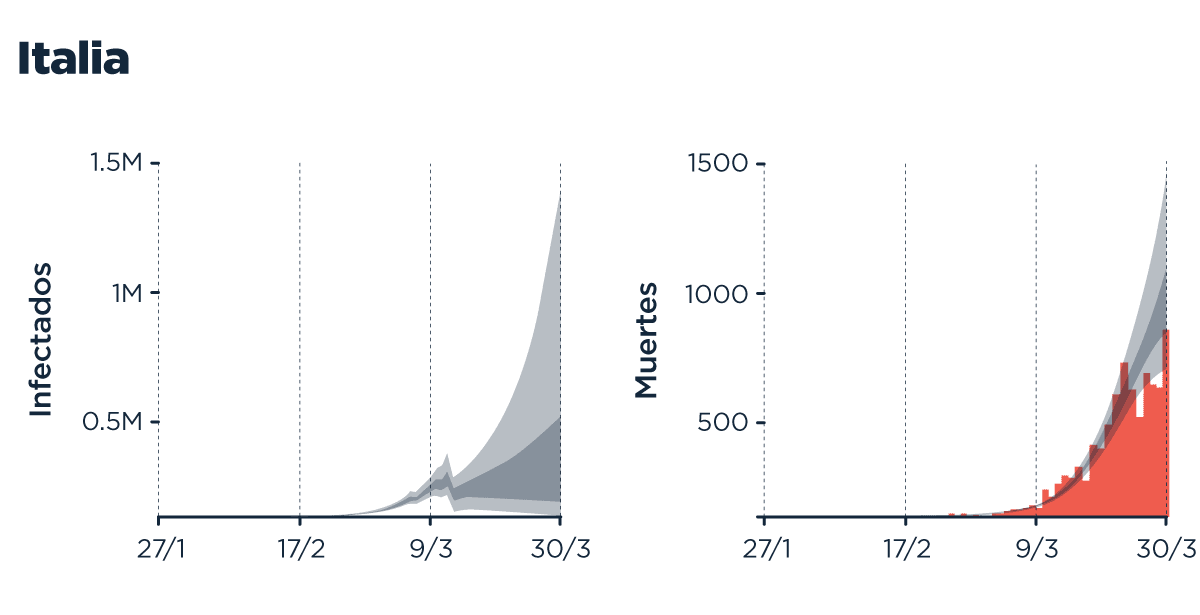
Curvas de contagios y muertes predichas por el modelo (datos en barras, estimaciones en bandas, 50 y 95% de confianza por opacidad).
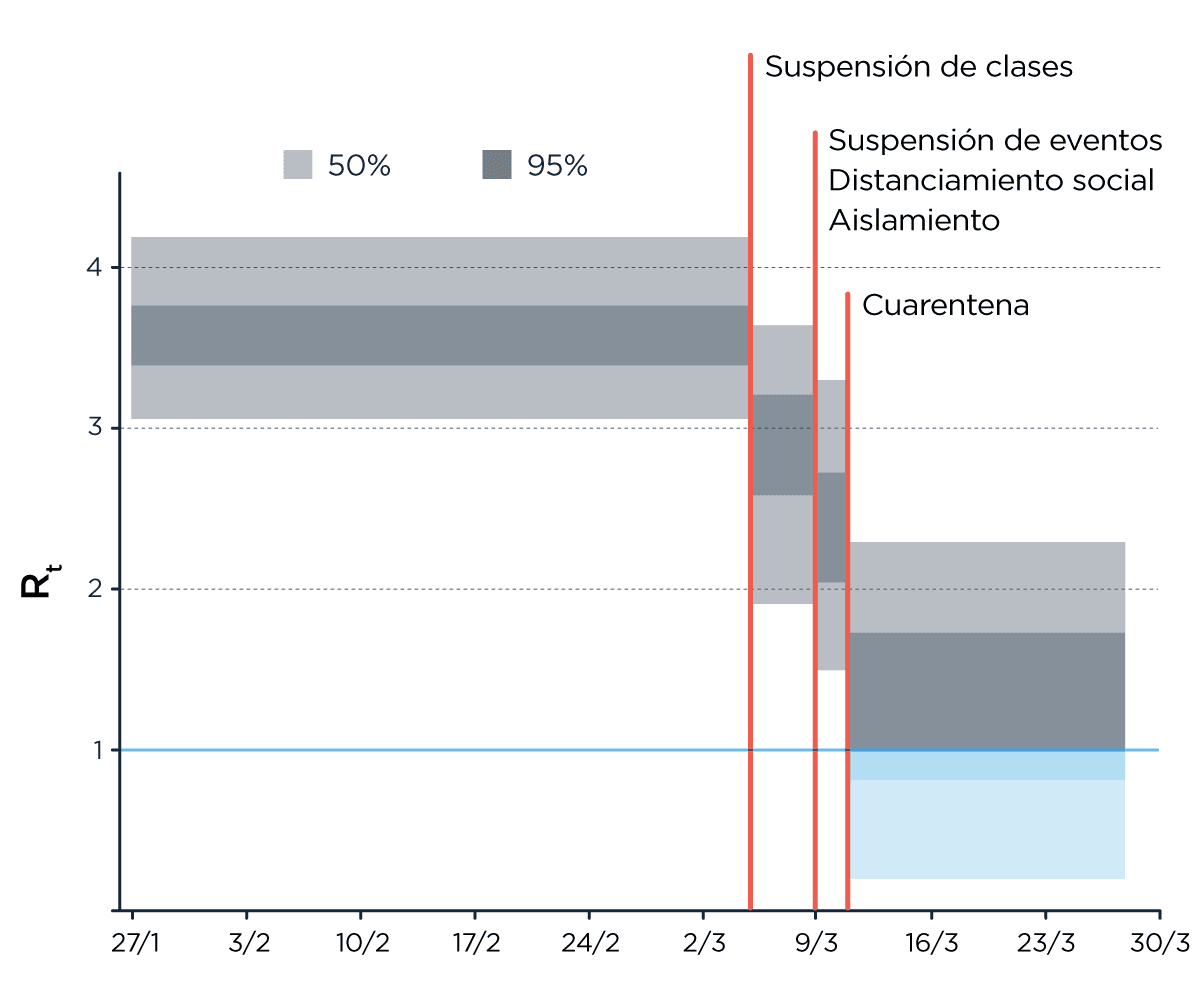
Estimaciones de R para cada etapa. R>1:BUUUU R<1:YAYYYYYY. Fuente
O sea que para lograr acercarse a R igual o menor que 1 (para controlar los contagios), se requiere sumar todas las intervenciones, siendo la cuarentena total el factor más ‘pesado’.
En este caso, lo que pudieron evaluar fueron todas medidas top down: un gobierno decide una medida general.
Esto comúnmente se relaciona con qué estrategia general sigue un territorio: en una estrategia de mitigación se trata de hacer un contagio controlado hasta que la población desarrolla inmunidad de grupo y se cuida a los grupos de riesgo por tener una población resistente (lo que pasaría normalmente con una vacuna, por ejemplo). Inglaterra amagó a ir para este lado hace una semana y hoy está en total lockdown.
Ir a cuarentena total implica haber ido por la estrategia de supresión, que es hacer todo para que ese R sea menor que 1, y que aparezcan menos casos mañana de los que hay hoy, así todos los días hasta que no haya casos nuevos.
¿Quiere decir eso que se soluciona el problema? DE NINGUNA MANERA. En un mundo de vacas reales y necesidades concretas, las cuarentenas necesariamente terminan. La pregunta es cuánto duran y cómo se relajan de manera de minimizar los costos humanos y los económicos. ¿Nos enfrenta esto a una disyuntiva sobre qué valor tiene una vida? De lleno. Este es un problema complejo, plagado de incertidumbre, donde seguramente la decisión que se tome sea la que busca el mejor equilibrio posible −por malo que sea− entre esos factores. El desafío va a ser estimar lo mejor posible ese equilibrio.
En todo el mundo, las cuarentenas han sido usadas para disminuir los casos, la velocidad de amplificación del virus y, principalmente, para ganar tiempo, el capital más grande en este contexto. Tiempo para ordenar y escalar el sistema de salud, tiempo para escalar los sistemas de diagnóstico, tiempo para entender opciones terapéuticas. Tiempo.
De este punto a que haya una vacuna y esté implementada a gran escala, toda medida es temporal y la cuarentena no termina. A lo sumo, cambia.
Receta para vacas más irregulares
Entendiendo ya las medidas desde los estados, una pregunta interesante sería qué y cuánto afectan los factores sobre los cuales las personas tenemos participación directa, desde el acatamiento de la cuarentena hasta el lavado de manos, en el progreso de la pandemia.
Cada vez que nos hacemos una pregunta sobre si una medida funciona, buscamos lo mismo que antes: entender cómo se traduce una acción al R. Así, cada acción es, de alguna manera, o acelerador o freno de la expansión. (En noticias relacionadas, GRAN laburo de GranData aproximando acatamiento usando datos de movilidad, se puede ver acá. También salió uno de Google recién recién).
Sabemos que ese número se afecta (entre otros) por:
- Cuánto contacto tenemos las personas entre nosotras.
- Qué riesgo de contagio acarrea cada contacto.
- Durante cuánto tiempo una persona puede contagiar.
Con eso en mente, podemos divertirnos usando modelos epidemiológicos ‘de juguete’ que están disponibles online. Y de ellos podemos aprender cosas como que evitar lugares por los que pasa mucha gente es buena idea porque baja la cantidad de contactos, que lavarnos las manos baja el R porque ahora cada contacto es potencialmente menos efectivo (para el virus) y que mientras una persona esté infectada, más contagios va a generar, entonces cualquier opción terapéutica o el rápido aislamiento de infectados cumple también el objetivo de bajar R.
Pero en este punto medio que estamos obligados a expandir de nuevo el modelo: existen asintomáticos. Personas que pasan un período en el que ni ellas mismas saben que están infectadas y potencialmente contagiando a otras (por suerte sí hay modelos que incorporan esos factores), pero, de nuevo, cada vez que nos acercamos a la realidad hay que agregarles más cosas a los modelos: desde distribuciones (que muchas veces no conocemos) a inputs de datos (que tampoco). Por ejemplo: ¿los asintomáticos son iguales para todas las edades? ¿Cuándo contagian y cuándo no? ¿Hay grados de contagiabilidad y asintomaticidad?
Hay modelos que incluyen ese tipo de ideas (está al final la lista-de-cosas-para-leer), por un lado convertir inputs directos (un valor ya) en distribuciones. Además, estos modelos incorporan precisamente ideas como la asintomaticidad. ¿Es mucha data y todo se vuelve recontra complicado? Y, sí. La vida misma.
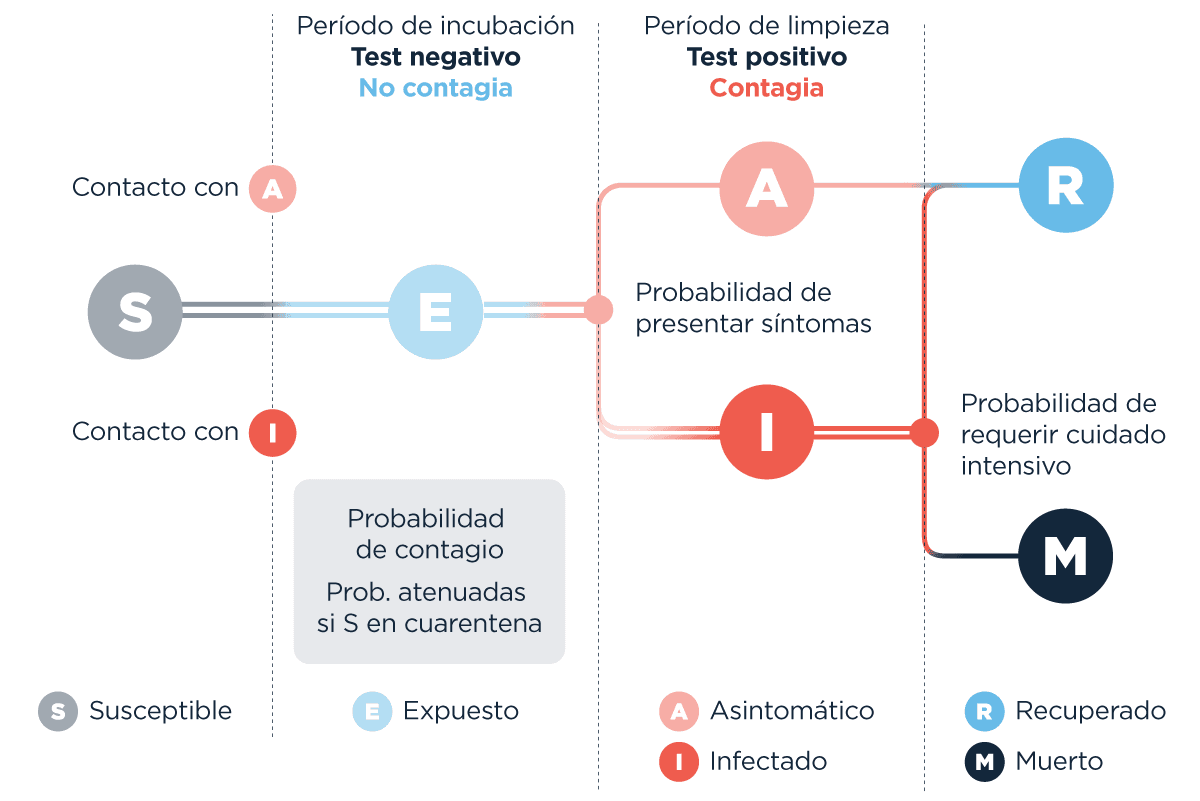
Esquema que hace que SIR sea insuficiente y ahora pase a ser SERIAM (?). Adaptado del trabajo de G. Soldano y J Fraire.
Otra pregunta que podemos hacernos es cómo distintas configuraciones de medidas y formas de cuarentena afectarían la curva de contagios y la ocupación del sistema sanitario. Hace dos semanas (equivalente a varios años en tiempos de pandemia), el equipo de Imperial College hizo exactamente eso:
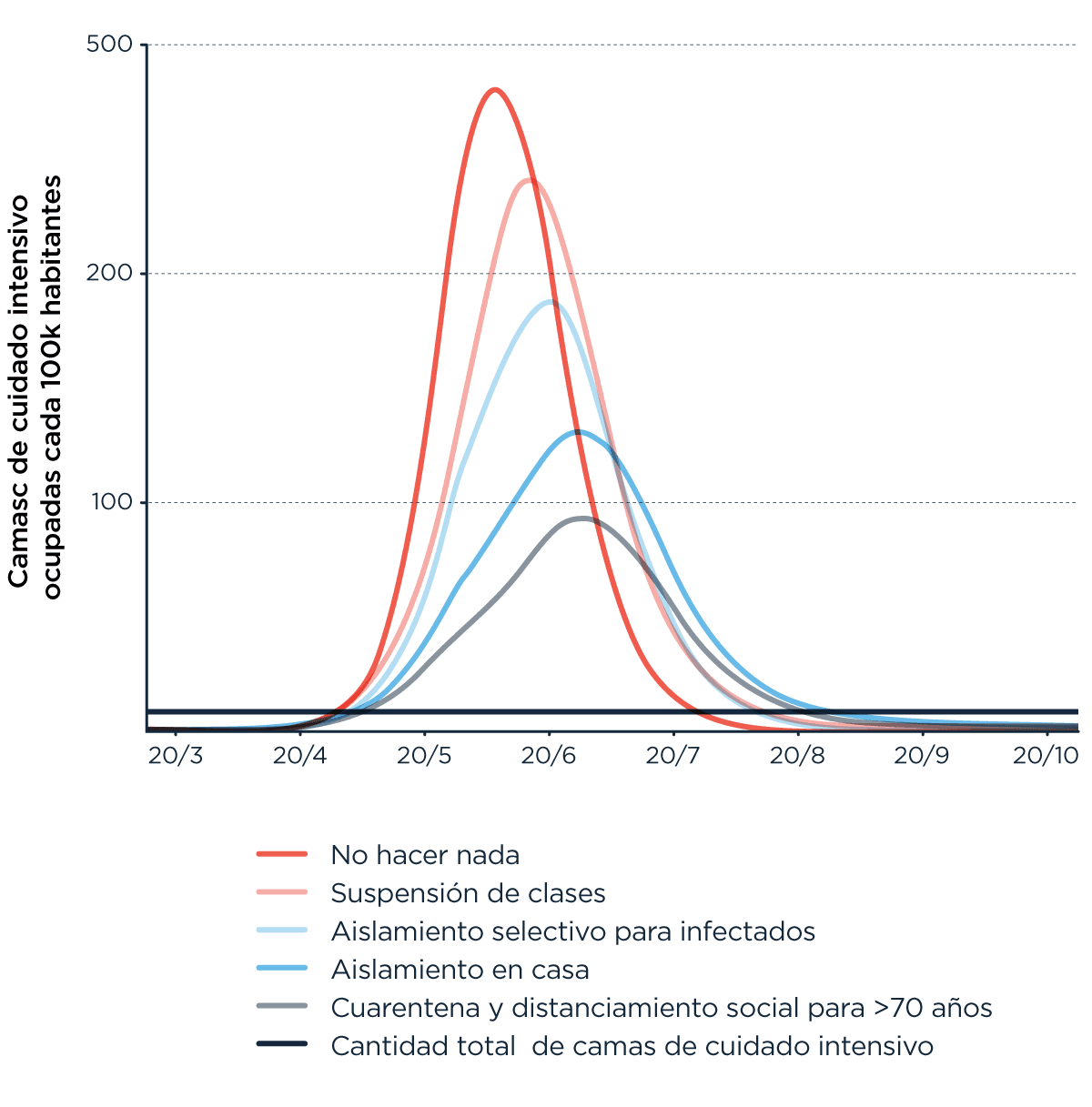
Así pudieron estimar cuánto funcionan (teóricamente) los distintos tipo de restricción, cada una con su propia potencia. Y antes de preguntar cómo es la estimación acá o cómo se compara la capacidad hospitalaria por centenar de miles de habitantes, el Diablo está en los detalles.
Una de las críticas que les hacen a los modelos de Imperial es, precisamente, cómo se relacionan esos números con la capacidad de carga real del sistema de salud, porque en ellos se calcula la cantidad de enfermos graves usando como input (como información que entra al modelo y que el modelo usa para hacer esas predicciones) tasas de mortalidad y letalidad sobre las que hoy todavía entendemos bastante poco, o cambian mucho en distintos territorios y dependen en gran medida del tipo, calidad y cantidad de testeos.
Tu vaca es más redonda de lo que puedo soportar
Cuando Imperial sacó sus primeras estimaciones se armó, además, rosca teórica. Por un lado, hubo críticas (algunas super razonables) sobre los puntos en los que estos modelos hacen más agua.
Una, por ejemplo, es que no se rescata que, en el mundo real, el R no es un promedio perfecto para la población y ni siquiera una distribución normal, sino que se parece más a otras distribuciones (distribuciones de cola larga), que incluyen posibilidades como los super spreaders, personas que son super contagiadoras y de las que tenemos varios ejemplos claros: un enfermo en Corea del Sur y una invitada de un casamiento en Uruguay. La cuestión humana se cuela de lleno y la idiosincrasia pesa. Hay personas a las que les copa estar en contacto con muchas personas y eso en un contexto epidemiológico hace diferencia.
Un detalle no menor del modelo de Imperial es que asume que la capacidad de carga del sistema de salud es la que hay y ya, no contempla iniciativas por expandir la disponibilidad de personal, materiales, etc.
Otro factor que los modelos de vacas esféricas como este ignoran es la posibilidad de remover activamente a los infectados de la población (y ni hablar de hacer rastreo de contactos y aislar a todos los posibles contagiados de primer orden hasta entender si están infectados).
Es más, se publicó hace nada un trabajo que evalúa y modela (con todas las limitaciones del caso) el rastreo de contactos y remoción, y parece que sería efectivo en la medida que se haga mediante una aplicación que sea utilizada por suficiente cantidad de personas en la población. Además, descomponen todavía más esa contagiabilidad y es un desperdicio no compartir el gráfico con el que lo cuentan:
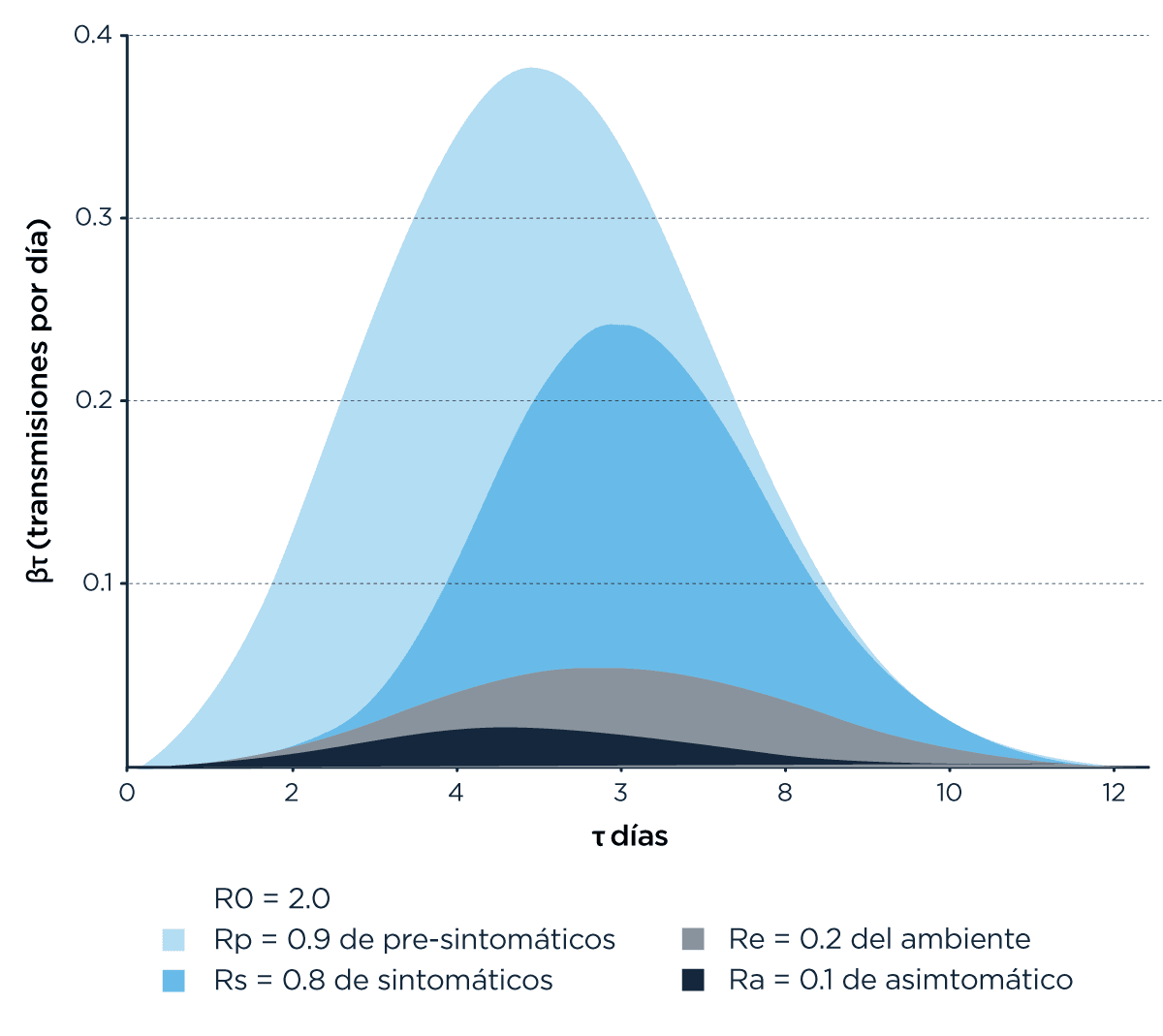
Lo que hicieron fue ponderar en distintas etapas el tiempo en el que cada persona es capaz de infectar a otras.
Un aporte super importante de ese mismo trabajo es haber podido estimar qué tanto te baja el R cada día que demorás entre confirmar un caso y aislarlo:
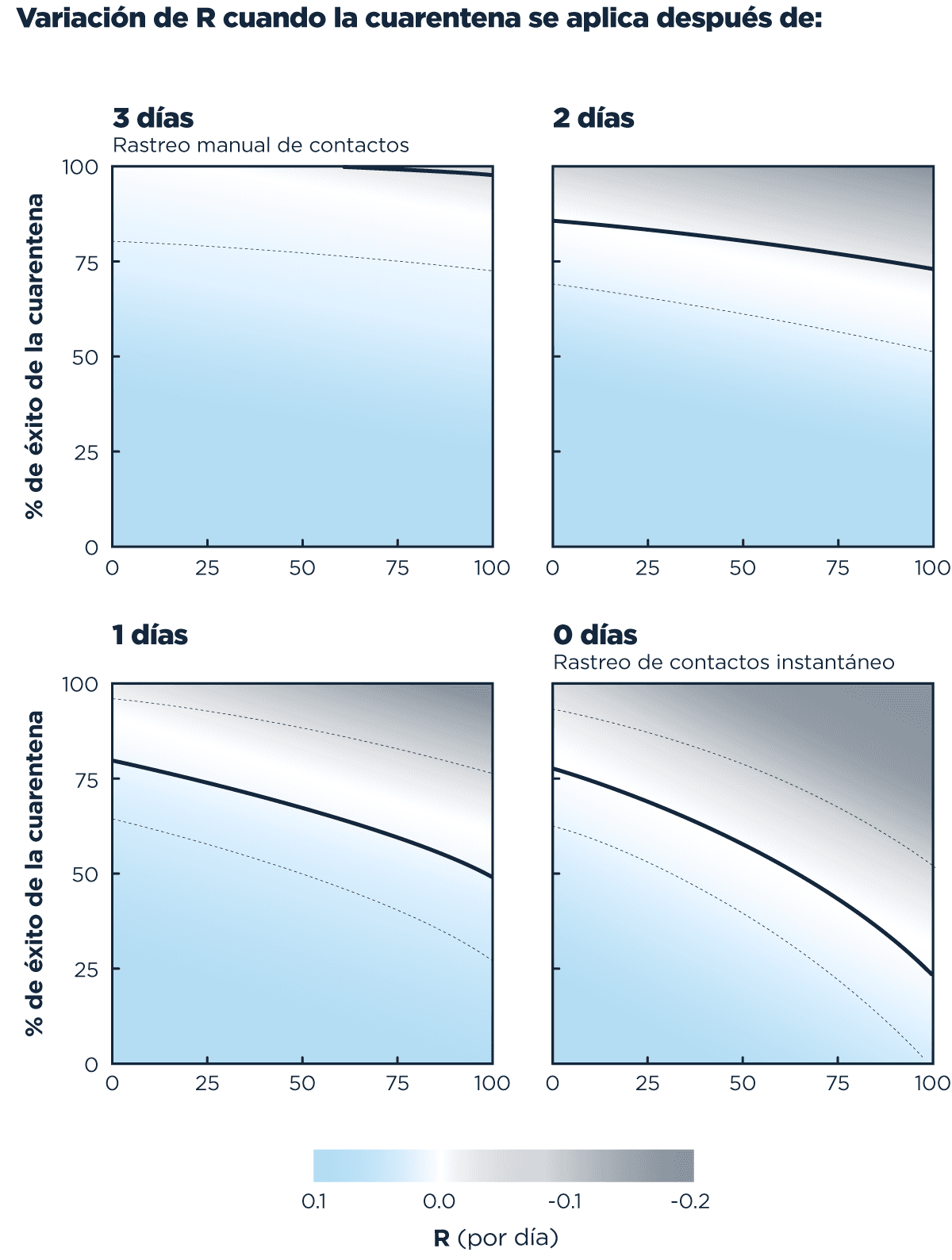
Mal y pronto, mientras más celeste, peor, más gris, mejor. De la línea negra para arriba estás disminuyendo R, de la línea negra para abajo, aumenta. Mientras más rápido se identifica el caso y más rápido se aísla, más arriba y a la derecha, menor R.
La moraleja: más rápido es mejor. ¿Dilema ético sobre privacidad, acceso del Estado a datos personales, etc? ¡Claro que sí! El equipo que lo publicó se encarga de discutirlo, dicen:
“Es probable que los requisitos para que la intervención sea ética y capaz de pedir esa confianza del público comprendan lo siguiente:
- Supervisión por una junta asesora inclusiva y transparente, que incluye a miembros del público.
- El acuerdo y la publicación de los principios éticos por los cuales se guiará la intervención.
- Garantías de equidad de acceso y tratamiento.
- El uso de un algoritmo transparente y auditable.
- Integrar la evaluación y la investigación en la intervención para informar el manejo efectivo de futuros brotes importantes.
- Supervisión cuidadosa y protecciones efectivas en torno a los usos de los datos.
- El intercambio de conocimientos con otros países, especialmente los países de bajos y medianos ingresos.
- Garantizar que la intervención implique la imposición mínima posible y que las decisiones en política y práctica se guíen por tres valores morales: igual respeto moral, equidad y la importancia de reducir el sufrimiento.”
De alguna manera, agregar todas estas complejidades al análisis lo llena de incertezas, pero admite y hasta empieza a proponer distintas opciones y caminos que llevan a la supresión total de circulación del virus. La pregunta se vuelve entonces a qué costo y cómo cada territorio en su situación particular política, social, histórica e idiosincrática puede o no encarar esas estrategias de para enfrentar la pandemia.
Pensar estos modelos desde la complejidad y la incertidumbre es vital para derrumbar la falsa sensación de seguridad que nos da creer que sabemos cuando capaz, en realidad, no sabemos tanto. Y es un proceso compartido que seguramente atravesamos profesionales de todas las disciplinas en este último mes.
Es tiempo de incertidumbre y complejidad, y probablemente la idea que debamos tener más clara es que si alguien te dice muy seguro lo que viene, está mintiendo, ya sea a vos o a sí mismo. Que las decisiones que se tomen, aún basadas en la mejor evidencia y modelos disponibles, van a ponerse después a merced del Universo como es, no cómo más o menos lo podemos modelar. Y que todo esto, eventualmente, pasará.
Cosas que deberías leer / ver / escuchar si te copa este tema:
- 3 Blue 1 Brown: es espectacular, somos fans, no hay mucho que decir más que ‘si vas a mirar algo, que sea esto’: https://www.youtube.com/watch?v=gxAaO2rsdIs
- La discusión de Nassim Taleb sobre el trabajo de Imperial, las limitaciones de los modelos y cómo la realidad real es difícil de comprimir: https://necsi.edu/review-of-ferguson-et-al-impact-of-non-pharmaceutical-interventions
- Si pinta pasión desenfrenada por modelos, es por acá (minuto 18 habla de SEIR): https://www.youtube.com/watch?v=MZ957qhzcjI&feature=youtu.be
- Un buen artículo de The Guardian medio hablando de lo mismo: https://www.theguardian.com/science/2020/mar/25/coronavirus-exposes-the-problems-and-pitfalls-of-modelling
- El paper de Imperial estimando R para distintas intervenciones en Europa (tiene un github, por si alguien quiere meter ciertos datos de cierto país y ver qué da): https://www.imperial.ac.uk/media/imperial-college/medicine/sph/ide/gida-fellowships/Imperial-College-COVID19-Europe-estimates-and-NPI-impact-30-03-2020.pdf
- En la UNC armaron un modelo interactivo y están actualizando (Gracias a Rodrigo Quiroga por el dato y por pegarle una leída al manuscrito): https://epacalc-arg.now.sh/. Recordar al usar que es un modelo de juguete, que está buenísimo para entender el proceso pero que no es soplar y hacer modelos epidemiológicos precisos aplicables a cualquier territorio en cualquier momento y ya.
- Germán Soldano y J. Fraire desarrollaron un modelo todavía más rico que estos, merece mirarlo, es medio para avanzados, pero si ya llegaste hasta acá, capaz que va, lo podés ver por acá.
Todo este texto viene un con gran ‘No soy epidemiólogo, pero’, que por suerte se ablanda gracias a la colaboración de una decena de personas de distintas especialidades que se tomaron el tiempo y trabajo de conversarlo. Gracias a Rocco Di Tella, Vale Sanabria, Juan Fraire, Andrés Babino, Enzo Tagliazucchi, Rodrigo Quiroga, Germán Soldano, Bruno Dagnino, Pablo Riera y al equipo Gato Sitio por siempre ayudar a minimizar imprecisiones.





{kind=link}