Un día los ingenieros marcianos lograron construir una interfaz gráfica para la realidad y así cambiaron para siempre su forma de experimentar el mundo. Antes de este hito vivían en la miseria y el miedo, ocultos al anochecer entre arena roja, piedras y copos de nieve. Pero la interfaz gráfica les permitió vencer a sus enemigos y florecer como la avanzada civilización tecnológica que imaginamos juntos a lo largo de este libro.
¿Cuál es el significado de este invento tan radical? ¿Qué es exactamente una interfaz gráfica para la realidad y por qué los ingenieros marcianos trabajaron durante décadas, quizás hasta siglos, hasta lograr diseñar y construir una?
A diferencia de nosotros, los marcianos tuvieron la desgracia de convivir y coevolucionar con una especie carnívora e inteligente, una especie que desarrolló un gusto por la carne marciana a lo largo de los milenios. Como si esto fuera poco, estos depredadores siempre tuvieron una enorme ventaja física sobre sus víctimas. Y si bien con el tiempo los marcianos lograron adaptarse y sobrevivir, esta competencia dejó marcas profundas y definitivas, incluso en la naturaleza de su conciencia. Una vez superado este obstáculo, entonces, se encontraron con un problema todavía mayor: ¿qué hacer con una conciencia evolucionada para superar a un depredador que ya no existe? Este es el interrogante que terminaría dando origen a su interfaz gráfica para la realidad.
La coevolución entre marcianos y depredadores es la historia de una frontera que separa el interior y el exterior de sus organismos. El sistema nervioso marciano reviste la parte externa de sus cuerpos y, por lo tanto, está a simple vista. En paralelo, los depredadores desarrollaron la capacidad para detectar tenues ondas electromagnéticas que se generan cuando la información circula por el cerebro de sus víctimas. Esta adaptación resultó ser inmensamente valiosa para los depredadores marcianos: les permitió, literalmente, ver la mente de sus presas. Los distintos patrones de destellos electromagnéticos emitidos por la superficie exterior de los cerebros marcianos podían delatar sus pensamientos e intenciones. Tan solo con la vista, un depredador podía conocer todo sobre una mente marciana: dónde estaba puesta su atención o en qué dirección empezar a correr para capturar a la presa. Esta ventaja de los depredadores fue tan grande que durante milenios estuvieron al borde de empujar a los marcianos hacia su extinción definitiva.
La inmensa presión selectiva sobre los marcianos resultó en una adaptación muy particular, una adaptación que terminaría garantizando la supervivencia de su especie, pero que, al mismo tiempo, cambiaría radicalmente la naturaleza de su conciencia. Tal como anticipamos en el primer capítulo, los marcianos son capaces de acceder y actuar directamente sobre los eventos neuronales que ocurren en su cerebro. Esto quiere decir, por ejemplo, que su experiencia subjetiva contiene información sobre la actividad en redes de neuronas y la concentración química de neurotransmisores. Los marcianos lograron equiparar la lucha contra sus depredadores adquiriendo acceso y control total sobre los estados de su cerebro. Así como los calamares liberan tinta para engañar a sus cazadores, los marcianos usaron su cerebro (y, por lo tanto, también sus pensamientos) con el mismo propósito.No es suficiente para los marcianos mostrar patrones de actividad cerebral engañosos: también deben ocultar los patrones de actividad cerebral responsables de exhibir patrones de actividad cerebral engañosos. De lo contrario, sus depredadores podrían darse cuenta de que están siendo engañados. En otras palabras: para los marcianos no alcanza con mentir, también deben ser buenos mentirosos.
Durante largos siglos, la existencia marciana se redujo a esperar que regresara el amanecer. Por la noche, los marcianos aparecían ante sus cazadores como patrones cambiantes de luz, cada uno de ellos sugerente de un estado mental diferente, que, a su vez, podía delatar sus planes de escape. Mientras que estos terribles depredadores se hicieron más fuertes y sensibles a esta tenue radiación cerebral, los marcianos aprendieron a modificar su cerebro para exhibir pensamientos engañosos y conducir a sus perseguidores a callejones sin salida. En otras palabras: mientras unos avanzaban en esta carrera evolutiva afinando su percepción, los otros hacían lo mismo pero con su introspección. Esta situación únicamente se pudo haber dado por la extraña reciprocidad entre exterior e interior que caracterizaba a los marcianos y sus depredadores.
Es inevitable que los marcianos hayan desarrollado un lenguaje muy diferente al nuestro. Recordemos las redes semánticas del capítulo anterior y la posibilidad de recorrerlas hacia adentro y hacia afuera, explorándolas en distintas resoluciones más o menos finas. El lenguaje marciano refleja la naturaleza de su experiencia subjetiva, y esta experiencia está marcada por información directa sobre el procesamiento de la información en su cerebro. En el idioma marciano, no encontramos mención a los qualia; en su lugar, leemos y escuchamos sobre liberación y concentración química de neurotransmisores, sobre ciertos tipos de actividad en redes de neuronas, y sobre el tráfico de moléculas cargadas a través de membranas celulares.
Este lenguaje es tan extraño como limitado: si bien es muy útil para conocer y manipular de forma voluntaria la actividad cerebral, es de difícil aplicación a los problemas teóricos y prácticos de la ciencia. El conocimiento requiere de síntesis y abstracción, y, por lo tanto, requiere de cierta capacidad para reducir la resolución en la red semántica del lenguaje. Vimos cómo los humanos enfrentamos grandes problemas para explicar el funcionamiento de nuestras mentes, precisamente porque los términos de nuestro lenguaje están optimizados para expresarse sobre otro nivel de resolución, que no es muy útil para dar explicaciones en términos neurobiológicos. Los marcianos enfrentan el problema opuesto: ¿cómo designar y entender las distintas regularidades del mundo exterior partiendo de un lenguaje optimizado para hablar sobre sus propios estados mentales? En su momento, algunos filósofos marcianos incitaron una rebelión contra la posición estándar, el eliminativismo, para abrazar una doctrina conocida como agregacionismo: la esperanza para entender el mundo físico reside en incorporar más conceptos que no se relacionen de manera obvia con el cerebro y sus realidades.
Así como los grandes intelectos de la humanidad chocaron una y otra vez contra el problema de la mente y la conciencia, los más grandes exponentes de la marcianidad tuvieron que enfrentar los enigmas del mundo exterior. Aunque muy despacio, los humanos avanzamos en el entendimiento de la mente: desarrollamos diagnósticos y tratamientos psiquiátricos, construimos mapas tridimensionales que representan distintas funciones cognitivas, y desarrollamos sofisticadas estructuras teóricas para relacionar el cerebro con los contenidos de la conciencia. Los marcianos hicieron avances comparables en su propio problema, complementario al nuestro: construyeron grandes ciudades y armaron poderosos ejércitos, persiguieron a sus enemigos hasta reducirlos a pequeños grupos aislados, e inventaron tecnologías para encontrar y eliminar estos grupos. Así fue como finalmente superaron esta amenaza existencial y aprendieron que la existencia no es lo mismo que la subsistencia.
Cuando el último de sus depredadores fue asesinado, los marcianos se convirtieron en camaleones que vivían en un mundo de criaturas ciegas al color. Lo que en el pasado fue su adaptación evolutiva más brillante se transformó de repente en una carga, una limitación. ¿Qué hacer con una conciencia evolucionada a medida de un propósito ya caduco? ¿Cómo escapar de una forma de subjetividad restringida y limitante?
Así fue como decidieron implementar una interfaz gráfica para la realidad. Cualquiera que haya utilizado una computadora puede entender el concepto. Sabemos que las computadoras procesan información modulando el flujo de electrones que pasan por los semiconductores de la unidad central de procesamiento (CPU). Pero muy rara vez interactuamos con las computadoras a ese nivel. Si fuese necesario, podríamos dar instrucciones a una computadora en términos de operaciones lógicas sobre bits individuales; estas estarían escritas en un complicado lenguaje directamente legible e interpretable por la máquina (código de máquina). O bien podríamos usar un lenguaje algo más intuitivo (ensamblador), que es interpretado y transformado (en la jerga, compilado) en instrucciones directamente interpretables por la máquina. Actualmente, la mayoría de quienes programan evitan las dificultades del código de máquina y el ensamblador mediante el uso de lenguajes de programación de alto nivel, como Python, Java o C. Estos lenguajes son más fáciles de utilizar porque incorporan cajas negras (subrutinas) para encapsular múltiples comandos en uno solo, de forma tal que la persona que programa no necesita repetirlos todos cada vez que los deba usar. Más aún, hoy la inmensa mayoría de quienes utilizan computadoras son incapaces de escribir una sola línea de código, porque la interacción humano-máquina se desarrolla mediante interfaces gráficas (el ejemplo más famoso es Windows). Este tipo de interfaz presenta imágenes al usuario y cada una de estas imágenes se asocia a una acción determinada (por ejemplo, copiar un archivo), lo que hace que operar la computadora adquiera una dimensión intuitiva. El uso de gráficos para comunicarse con el usuario no reemplaza el código de máquina: cada operación hecha sobre la interfaz gráfica se traduce inmediatamente en instrucciones interpretables por la computadora. El usuario no tiene acceso a ese código y desconoce por completo su existencia, pero simultáneamente lo genera cuando actúa sobre la interfaz gráfica. Esta es la diferencia principal respecto del encapsulamiento mediante subrutinas empleado por un programador, quien usa cajas negras por conveniencia aunque también conoce lo que hay en su interior. El usuario de una interfaz gráfica opera en un nivel completamente distinto: no solamente no conoce el código que se genera a partir de su interacción con el sistema, sino que tampoco tiene forma de conocerlo.
Los marcianos buscaban una manera de experimentar el mundoPara facilitar intuiciones llamamos a esta nueva forma interfaz gráfica. En realidad, se trata de una interfaz experiencial, que se extiende a modalidades sensoriales más allá de la visión. y actuar sobre él sin tener que preocuparse por los detalles de los procesos neuronales subyacentes, aquellos procesos que en su momento debieron manipular con cuidado para engañar a sus enemigos mortales. Necesitaban encontrar una forma de representar información visual sin ocuparse de la forma en que sus neuronas detectaban bordes, colores, texturas, movimientos y objetos, así como una forma de hablar y moverse sin tener que activar las secuencias exactas de neuronas responsables de poner en moviento cada músculo y juntura en los dedos, piernas y en su tracto vocal. Querían poder olvidar con la misma facilidad con que llevamos un archivo a la papelera de reciclaje.
Los marcianos que conocimos en el primer capítulo ya habían logrado este cometido hacía muchísimo tiempo. Sus libros de historia registran los ensayos y errores que culminaron en el desarrollo de una interfaz capaz de representar la realidad misma. También registran una época de confusión e inseguridad, incluso luego de haber alcanzado su objetivo. Inmersos en un mundo nuevo y diferente, los marcianos tuvieron que contradecir sus instintos más primitivos para abandonar una forma de percepción que estaba marcada a fuego en su código genético. Muchos nunca lo lograron y fueron olvidados en el camino; otros, en cambio, se arrojaron hacia el futuro sin mirar atrás. Aunque su conciencia haya cambiado, todos mantienen recuerdos sobre la forma antigua de ver la cosas y también son capaces de evocarla a voluntad, porque la interfaz gráfica es incapaz de suprimir por completo la verdadera naturaleza de los marcianos. La nueva forma de conciencia debe aprenderse. Los primeros en intentar comunicar estas nuevas sensaciones fueron los artistas, quienes capturaron sus nuevas experiencias subjetivas en dibujos y pinturas, representando un punto medio entre su nueva y su vieja forma de percepción, como si fuesen los primeros dibujos de un niño que recién aprende a ver el mundo:
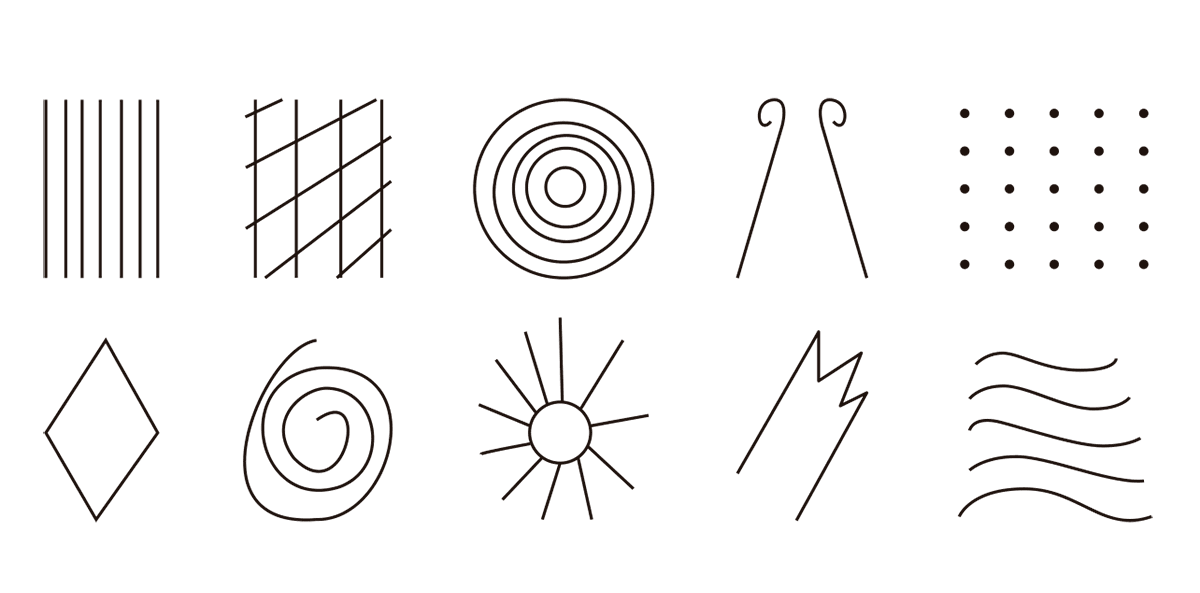
FIG. 10.1 VISIONES DE LOS MARCIANOS
Nuestra situación es simétrica respecto de la situación marciana si intercambiamos exterior por interior. Nuestros cerebros evolucionaron partiendo de pequeños organismos con células especializadas en transmitir información entre dos puntos del espacio. Al principio, estas células les permitían a los organismos reaccionar ante información del entorno; por ejemplo, nadar en la dirección donde aumenta más rápido la concentración de nutrientes. Los sistemas nerviosos estaban formados únicamente por arcos reflejos: circuitos cerrados y relativamente cortos entre una neurona sensorial y una neurona motora, como hilos que llevan información en una sola dirección. Con el tiempo, la evolución condujo a circuitos más complejos capaces de mantener la información circulando para relacionarla con nuevos estímulos provenientes del entorno e integrarlos a lo largo del tiempo. Dejó de ser claro en qué dirección fluía la información: los hilos se anudaron y surgieron la cognición y las mentes. Las activaciones ante estímulos pasados empezaron a influir en la respuesta a estímulos posteriores; es decir, los sistemas nerviosos tuvieron por primera vez una forma de memoria. A partir de este momento, estos organismos lograron hacer más que reaccionar ante su entorno y adquirieron funciones que identificamos con formas rudimentarias de aprendizaje, memoria, atención y toma de decisiones. Nuestro cerebro es una de las formas presentes que toma este proceso evolutivo; hoy hay nudos por todas partes, y si bien el nuestro es el más complejo, no es fundamentalmente distinto a todos los demás.
El órgano encargado de negociar nuestra relación con el exterior se encuentra profundo en el interior de nuestro cuerpo, protegido por el cráneo, e inaccesible a la percepción de cualquier organismo. No existió jamás sobre la superficie terrestre una especie capaz de observar nuestros pensamientos y, por lo tanto, jamás sufrimos la clase de presión evolutiva que determinó el curso biológico de los marcianos. En contraste, los seres humanos fuimos durante miles de años la presa predilecta de depredadores mucho más fuertes, ágiles y perceptivos que nosotros. Los registros fósiles muestran tigres gigantescos con dientes que parecen haber evolucionado con el propósito específico de penetrar el cráneo humano. Pero estos tigres ya no existen: logramos perpetuar nuestra especie, aunque no gracias a nuestras capacidades introspectivas, sino gracias a nuestra visión binocular, nuestros pulgares oponibles y nuestras capacidades cognitivas. En síntesis, gracias a nuestra capacidad para percibir, modelar, predecir y modificar el mundo exterior.
Los humanos ya venimos con una interfaz gráfica para la realidad instalada.Tal como la de los marcianos, en realidad nuestra interfaz va más allá de la percepción visual. Todo lo que escribimos sobre la percepción visual puede traducirse a otras modalidades sensoriales; quien lee puede hacer el ejercicio de traducción si lo considera necesario. Esta es la forma en que nuestra conciencia se encuentra encapsulada respecto de nuestro cerebro. Esta interfaz es tan crucial para nuestra supervivencia que instintivamente tratamos de expandirla, construyendo dispositivos de realidad aumentada para compartimentar aún más la información que aparece en nuestra experiencia subjetiva. Imaginemos el siguiente futuro: los ingenieros humanos aprenden cómo construir un implante cerebral que instala una interfaz de más alto nivel en nuestra conciencia, algo análogo a instalar un Windows 8 en una computadora que antes tenía un Windows XP.Tanto el Windows 8 como el XP poseen interfaces gráficas que simplifican el uso de la computadora, lo que evita al usuario tener que invocar comandos en una consola para interactuar con el sistema operativo. A pesar de estas similitudes, el Windows 8 es infame por simplificaciones excesivas, ya que esconde funciones útiles y limita considerablemente la intervención del usuario en su propia computadora. El resultado sería similar a vivir en un videojuego: no tendríamos que ocuparnos de ciertos detalles rutinarios pero fundamentales para sobrevivir. La necesidad de dormir, comer o hacer un trámite se podría satisfacer apretando un botón en la interfaz. Así como no tenemos que pensar en cada respiración o cada latido de nuestro corazón, el nuevo implante ofrecería la posibilidad de automatizar muchas otras actividades y dejar nuestra conciencia libre para enfocarse en cosas que realmente importan, como la creatividad o el hedonismo. Podemos imaginar juegos de computadora que hagan opcionales ciertas tareas repetitivas, pero nunca tendría sentido hacer que el objetivo principal del juego se vuelva opcional. De forma análoga, esta interfaz gráfica para la realidad tendría botones para “comer” o “dormir”, pero no para “crear” o “disfrutar”.
Esta interfaz no encapsularía únicamente actividades repetitivas, sino también parte del contenido consciente asociado a nuestra percepción sensorial. La forma en que hoy reconocemos objetos es jerárquica: se basa en agregar información sobre las partes para llegar a una conclusión sobre el todo. Así, por ejemplo, identificamos una cara como el resultado de agrupar dos ojos, una nariz y una boca. Pero esto no tendría por qué ser así. Podríamos, por ejemplo, disponer de una sensación subjetiva única y diferente asociada a cada cara distinta, completamente independiente de las sensaciones subjetivas de ojos, narices y bocas. El implante sería capaz de simplificar nuestra percepción al permitirnos discriminar objetos sin necesidad de evaluar la identidad de sus partes. Imaginemos a una ajedrecista capaz de percibir cada configuración del tablero de forma diferente sin tener que examinar con detalle la ubicación de cada una de las piezas, de la misma forma en que ahora percibimos distintos colores o sonidos.
Si este implante fuese muy exitoso (y no hay razón para pensar que no lo sería), las sucesivas generaciones de humanos perderían de a poco el conocimiento sobre cómo eran las cosas antes de la interfaz gráfica. Quizás hasta ignorarían que hubo un antes. Inevitablemente, alguien se intentaría rebelar contra esta interfaz gráfica, así como ocasionalmente escuchamos discursos sobre la ineficiencia de Windows y la necesidad de migrar hacia otros sistemas operativos manejables mediante terminales de texto. Este rebelde argumentaría que librar nuestra conciencia de experiencias cotidianas simples y repetitivas nos aparta excesivamente de aquello que nos vuelve humanos. Una eventual campaña de desinstalación de implantes revelaría una nueva (aunque antigua) forma de conciencia, más detallada en algunos aspectos y menos en otros, y con una mayor prevalencia de ciertos contenidos repetitivos (como bañarse, cepillarse los dientes, comer y dormir).
Imaginemos ser parte de esta generación que decidió desinstalar el implante de su cerebro. ¿Cómo nos sentiríamos? ¿Podemos imaginar tener que intervenir, de repente, en un montón de procesos que antes estaban automatizados? ¿Cómo sería perder ciertas sensaciones subjetivas para siempre, cambiándolas por un agregado de otras sensaciones?
Ahora imaginemos que ya tenemos un implante instalado en el cerebro, un implante cuya función es análoga a la del implante de los párrafos anteriores. Es decir, imaginemos que ya interactuamos con el mundo mediante una interfaz gráfica que simplifica nuestras acciones y nuestras percepciones. Remover este implante cambiaría nuestra mente y nuestra conciencia de la misma manera que el cambio que imaginamos hace un momento, excepto que en vez de llevarnos a la forma en que hoy percibimos el mundo, nos llevaría a una forma diferente. ¿Cómo se sentiría? ¿Qué podríamos aprender sobre nuestras conciencias si lográramos esta transformación?
Este libro se distingue de otros al menos en lo siguiente: usamos redes neuronales artificiales para explicar y apoyar ciertas ideas e intuiciones. Puede que el motivo sea generacional. A diferencia de otros autores algo mayores, mi carrera científica empezó cerca del año 2010 y, por lo tanto, coincidió plenamente con el renovado auge del aprendizaje profundo y las redes neuronales artificiales. Aprendí neurociencia a la par que aprendizaje automático (machine learning), el campo de la computación que trata sobre encontrar y generalizar información a partir de ejemplos. Durante una etapa de mi vida, gané mi sueldo desarrollando e implementando algoritmos de este tipo, que se aplicaban a la resolución de importantes problemas del capitalismo contemporáneo; por ejemplo, cómo asignar vendedores a distintos clientes, o cómo lograr que las personas pasen la mayor cantidad de tiempo en una determinada página web. Aunque esta lucrativa parte de mi carrera quedó definitivamente en el pasado, ya no puedo evitar pensar en muchos problemas científicos a la luz de las herramientas que utilizaba por aquel entonces. Y dentro de todas esas herramientas, creo que las redes neuronales artificiales son una de las mejores metáforas para pensar sobre la mente y la conciencia.
En un capítulo anterior, entendimos el tipo de red neuronal conocida como autocodificador como una forma de comprimir información sin perder su esencia, es decir, sin perder lo mínimo indispensable para luego poder reconstruir los datos con un grado aceptable de fidelidad. Luego usamos los autocodificadores como un recurso teórico para entender el alcance de la perspectiva estadística en el estudio de la conciencia. Ahora vamos a introducir otro modelo de red neuronal artificial, uno especialmente útil para examinar intuiciones sobre la interfaz gráfica para la realidad: las redes neuronales convolucionales.
Una red neuronal convolucional consta de varias capas sucesivas, cada una de ellas con un menor número de neuronas. La entrada es una imagen bidimensional, y un objetivo típico es determinar si la imagen contiene cierto objeto. Imaginemos, entonces, que estamos desarrollando un detector de caras y que para ello implementamos una red neuronal convolucional que toma fotos como input y devuelve dos números como output. Estos números corresponden a la probabilidad de que haya una cara en la imagen y de que no la haya (por lo tanto, los dos números suman 1).La probabilidad de que suceda A o B, p(A o B), se calcula como la probabilidad de que suceda A más la probabilidad de que suceda B, p(A) + p(B). En el caso de que A = hay una cara y B = no hay una cara, p(A) + p(B) = 1 (es decir, certeza absoluta), porque o bien hay una cara o bien no la hay.
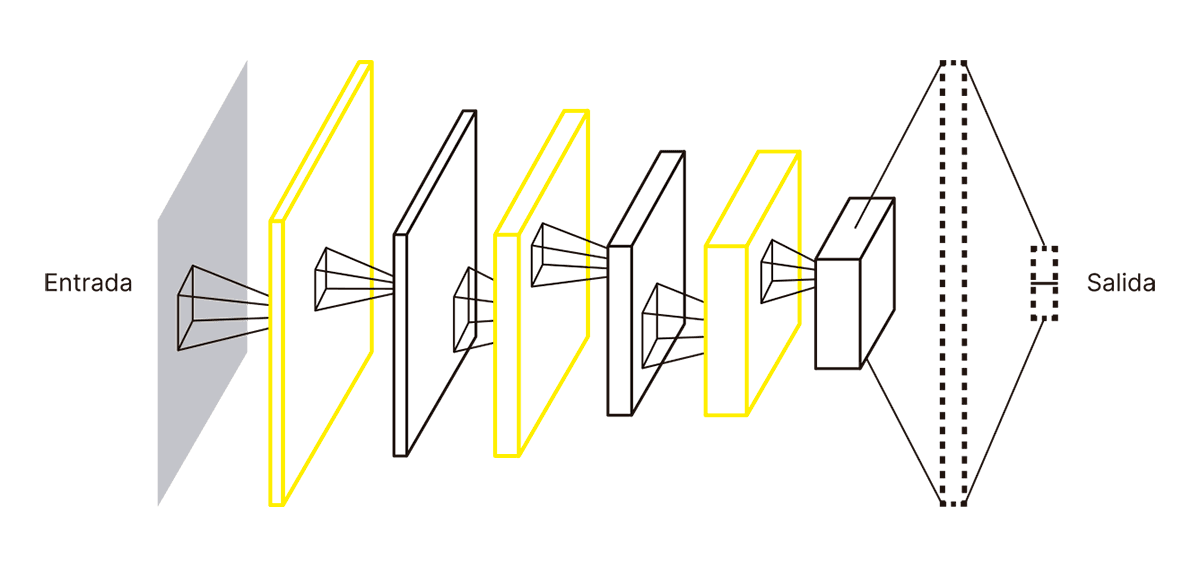
FIG. 10.2 RED NEURONAL CONVOLUCIONAL
La red neuronal convolucional consta de múltiples capas sucesivas que van representando información relevante para la tarea. Cada neurona de la segunda capa (representada como un rectángulo amarillo) recibe una parte de la imagen de entrada. En el diagrama se ve un rectángulo que selecciona una parte de la imagen y la proyecta a una neurona en la segunda capa. Esta proyección se basa en computar un promedio sobre la parte seleccionada de la imagen; la operación de ir moviendo el rectángulo que selecciona una parte de la imagen y computando su promedio se denomina convolución (de ahí el nombre de la red). Como la segunda capa se forma promediando partes de la imagen de entrada y alimentando con cada promedio una neurona, la cantidad de neuronas es necesariamente menor a la cantidad inicial de píxeles. Este proceso se repite: las neuronas de la tercera capa reciben el promedio de un subconjunto de neuronas en la segunda capa; las de la cuarta, un promedio de un subconjunto de neuronas en la tercera, y así sucesivamente. En la figura vemos cómo los rectángulos se hacen cada vez más pequeños debido a que las sucesivas convoluciones reducen el tamaño de las imágenes representadas en la red neuronal (por ejemplo: si promediamos 3 x 3 = 9 píxeles para obtener cada píxel de la capa siguiente de la red, esta capa tendrá naturalmente menos píxeles que la anterior).Los rectángulos se hacen también más anchos. Esto significa que en las capas sucesivas los fragmentos de las capas anteriores se promedian de varias formas distintas, de manera de resultar en múltiples números por fragmento. La última capa consiste en una red neuronal completamente conectada (es decir, no convolucional) que transforma la información en dos números interpretables como las probabilidades de que haya o no una cara en la imagen.
La red neuronal recibe un ejemplo de entrenamiento, es decir, una imagen en la que puede o no haber una cara. Luego, propaga esta imagen por sus sucesivas capas hasta computar una probabilidad. Si la red neuronal todavía no está entrenada, no tenemos por qué esperar que pueda detectar caras correctamente. En este caso, por ejemplo, podría devolver una probabilidad alta de “no cara” cuando claramente hay una cara presente en la imagen. Cada vez que esto sucede, se modifican los parámetros numéricos involucrados en las operaciones de promediado, de forma tal que ahora la red neuronal devuelve una respuesta más cercana a la correcta.Este es el paso más difícil. Llevó muchos años descubrir cómo adaptar una red neuronal en base al error cometido en un ejemplo de entrenamiento. La solución encontrada se llama retropropagación (backpropagation) y consiste en ajustar las transformaciones realizadas por las capas siguiendo un orden que va desde la capa más cercana a la salida hasta llegar a la capa inicial. Para quienes tengan inclinación matemática: la retropropagación permite computar el gradiente de la función de costo y, por lo tanto, permite optimizar los parámetros mediante un algoritmo conocido como descenso por el gradiente (gradient descent). Este proceso se repite con miles y miles de imágenes. En cada paso, la red neuronal se modifica un poco para estar más cerca de cumplir su función. Gradualmente, las operaciones de promediado que transforman una capa en la sucesiva empiezan a incorporar información relevante presente en los ejemplos de entrenamiento. Finalmente, la red neuronal es capaz de detectar correctamente todas las caras en el conjunto de entrenamiento. Entonces se la evalúa con imágenes que no estaban presentes en el conjunto de entrenamiento. Esta es la prueba definitiva: si la red logra generalizar aceptablemente lo que aprendió durante el entrenamiento a imágenes nuevas, consideramos que el proceso fue exitoso.
¿Por qué las redes neuronales convolucionales se construyen de esta manera? Notamos que las capas sucesivas se forman mediante un agregado de las capas anteriores.Otra propiedad importante de las redes neuronales convolucionales se denomina invarianza de traslación y les permite detectar objetos independientemente de su posición en la imagen de entrada. Esto sugiere que las redes neuronales descomponen la imagen de entrada en subimágenes pequeñas, que luego unen en capas sucesivas para formar subimágenes compuestas, hasta finalmente construir subimágenes directamente transformables en probabilidades al llegar a la última capa de la red. Observamos que existe una analogía con el proceso de reconocimiento facial: primero identificamos partes de la imagen, como ojos, narices y bocas, y luego agregamos la información para decidir si lo que estamos viendo es o no una cara.
Las redes neuronales convolucionales son útiles porque se aplican directamente a las imágenes sin necesidad de aplicarles transformaciones previas. Antes de la explosión de las redes neuronales cerca del año 2010, el reconocimiento de objetos era un proceso muy complicado, prácticamente un arte. Entre otras cosas, requería heurísticas, es decir, representaciones determinadas de forma explícita por los programadores para que las imágenes sean útiles en el proceso de aprendizaje automático. Estos pasos previos buscan poner en evidencia aquella información útil para determinar la presencia de un determinado objeto. El problema es que este análisis suele estar basado en la intuición de los programadores y puede requerir una dosis considerable de prueba y error. En contraste, las redes neuronales convolucionales son capaces de encontrar por sí mismas estas transformaciones: esto es exactamente lo que hacen en las sucesivas capas de la red. La primera capa sirve para poner en evidencia información útil para la segunda, la segunda para la tercera, y así sucesivamente. Esta autosuficiencia hace que las redes neuronales convolucionales sean muy útiles y poderosas para reconocer objetos, especialmente si están entrenadas con grandes volúmenes de datos.
Recordemos cómo las redes neuronales, personificadas por AlphaZero, transformaron repentinamente el mundo del ajedrez y del go, y dejaron obsoletos a los algoritmos más poderosos conocidos hasta el momento (capítulo 5). Algo similar sucedió promediando el año 2010 con las redes neuronales convolucionales: muchas competencias organizadas sobre reconocimiento de imágenes dejaron de tener sentido. Resulta que estas redes alcanzaron puntajes tan altos que ya no tenía gracia continuar con las competencias en años posteriores. Hoy por hoy, las redes neuronales convolucionales pueden superar a los seres humanos en el reconocimiento de ciertos objetos, incluyendo caras de otros humanos. Aunque no hay nada mágico detrás de este éxito rotundo: se trata de algoritmos que se conocían desde hace muchos años. El auge de las redes neuronales tiene que ver con la enorme disponibilidad de datos (cortesía de internet) y con el desarrollo de hardware muy eficiente para el entrenamiento (unidades de procesamiento gráfico o GPU).
Dijimos que la arquitectura de las redes neuronales convolucionales imita la forma en que reconocemos objetos en nuestra percepción visual, con capas que detectan información útil en escalas cada vez mayores y de forma jerárquica. Pero esto es únicamente una analogía. La pregunta interesante es: ¿las redes neuronales convolucionales representan información visual de la misma forma en que la representa nuestro cerebro? Cuando decimos que las redes convolucionales detectan subimágenes y luego las agregan para detectar imágenes compuestas, ¿podemos afirmar que la corteza visual del cerebro detecta las mismas subimágenes y procede a agregarlas de formas similares? Maravillosamente, la respuesta a estas preguntas es, en gran medida, afirmativa. Pero antes de entender estas similitudes, tenemos que familiarizarnos con el funcionamiento de la corteza visual.
Cada neurona de la corteza visual primaria posee un campo receptivo, es decir, una porción del campo visual a la que responde. El campo receptivo de las neuronas de la corteza visual primaria se corresponde con el fragmento de la imagen de entrada que se proyecta en la neurona de la primera capa de la red. En 1981, David Hubel y Torsten Wiesel ganaron el Premio Nobel de Fisiología por demostrar que las neuronas de la corteza visual primaria responden a la orientación de la imagen en su campo receptivo. Segmentos con distinta orientación activan preferencialmente distintas neuronas de la corteza visual primaria; además, las neuronas que responden a una misma orientación se encuentran próximas en la corteza visual, agrupadas formando columnas perpendiculares a la superficie cortical. La corteza visual primaria es un detector de bordes, y, por lo tanto, sus neuronas se activan selectivamente ante la presencia de segmentos orientados dentro de sus campos receptivos.
Las neuronas de la corteza visual primaria se proyectan a otras regiones con neuronas que responden a combinaciones más complejas de los segmentos orientados, junto con otras propiedades tales como color, textura y movimiento. Este proceso de composición gradual llega a su conclusión en la corteza temporal inferior, donde es posible encontrar neuronas que responden a objetos específicos, por ejemplo, a caras de personas.Más aún, tal como demostró el neurocientífico argentino Rodrigo Quian Quiroga, estas neuronas responden a conceptos específicos. Por ejemplo, es posible encontrar neuronas que responden a la cara de Maradona, pero también a su nombre (escrito o pronunciado) o a otras referencias directas a su persona.
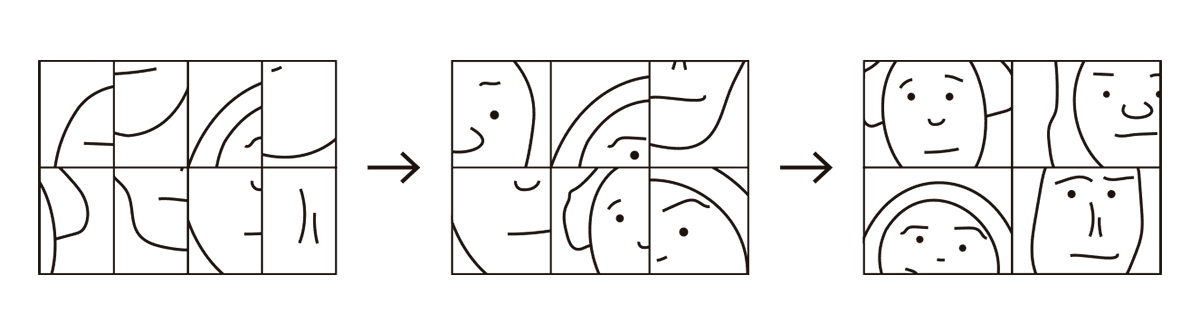
Las redes neuronales artificiales proceden de forma similar. Las neuronas de las primeras etapas son capaces de aprender información sencilla relacionada con segmentos orientados. Las neuronas de capas intermedias aprenden combinaciones más complejas de estos segmentos, por ejemplo, distintas partes de caras. Por último, las capas finales de la red responden ante la presencia de caras enteras, o incluso de ciertas caras específicas si fueron entrenadas para tal fin.
FIG. 10.3 REPRESENTACIÓN EN LAS CAPAS INTERMEDIAS DE UNA RED CONVOLUCIONAL
Cuando entrenamos una red neuronal, estamos principalmente interesados en lo que aprenden las neuronas de las últimas capas, porque estas son las neuronas que representan la información que queremos identificar en las imágenes. Si bien las capas anteriores son muy importantes, la información que representan permanece oculta para el usuario de la red. Siempre y cuando su interés esté limitado a la aplicación práctica de la red para detectar objetos, lo único que debe conocer el usuario es lo que se encuentra a la salida. Sería poco práctico o incluso confuso inundar al usuario con la información correspondiente a las capas internas; por lo tanto, la red encapsula esta información en una caja negra que es inaccesible excepto para aquellos que quieran entender cómo funciona.
Esta es la intuición que invocamos al decir que la conciencia funciona como una interfaz gráfica simplificada para la realidad. En capítulos anteriores, identificamos la conciencia con la disponibilidad global de la información en el cerebro, un proceso de publicación que permite el acceso a la información por parte de múltiples funciones cognitivas. El acceso al espacio global de trabajo implica capacidad para actuar de forma arbitraria sobre la información: reportarla, recordarla, usarla para la toma de decisiones, transformarla y vincularla con información obtenida en el pasado, así como proyectarla para predecir el futuro. Pero ¿sería útil acceder de esta forma a toda la información representada en el sistema visual? Podemos hacer el ejercicio de imaginar cómo sería si esto sucediese. Un tigre dientes de sable se aparece ante nosotros en medio de la sabana, pero todavía no somos conscientes de su identidad. Durante el tiempo que dura el procesamiento de la información visual en nuestro cerebro, una imagen se forma gradualmente en nuestra conciencia. Primero, somos capaces de reportar la forma en que los contornos de la imagen se orientan en el espacio; luego, nuestra cognición accede a fragmentos más complejos formados por la intersección de múltiples segmentos. Empiezan a formarse texturas, luego aparecen colores y también movimientos; finalmente percibimos ojos, pelos y garras. Es entonces cuando por fin se encienden las neuronas que representan el concepto tigre de dientes de sable y empezamos a correr lo más rápido posible para seguir con vida.
Pero esto no es lo que sucede. Nuestra interfaz gráfica para la realidad se encarga de barrer todas estas operaciones intermedias por debajo de la alfombra, presentándonos únicamente el resultado final. La información presente en las etapas intermedias del procesamiento visual es de dudosa utilidad para nuestra supervivencia y, por lo tanto, ¿por qué accedería al espacio global de trabajo?Hay excepciones que tienen que ver con respuestas que ocurren en ausencia de conciencia; es decir, con respuestas que no están mediadas por la propagación de la información al espacio global de trabajo. La información sobre el movimiento de objetos, por ejemplo, puede guiar el comportamiento humano incluso si no es representada de forma consciente (este es el caso de la visión ciega, que discutimos en capítulos anteriores). ¿De qué nos sirve disponer únicamente del contorno de la imagen? ¿Cómo es que algunos ojos y dientes flotando en el espacio podrían ayudarnos a entender si existe o no una amenaza inminente? Esta encapsulación de la información es análoga a la forma en que el implante que imaginamos encapsula la información visual para reemplazar imágenes compuestas por una única y nueva sensación subjetiva (por ejemplo, “sensación de tablero de ajedrez #438475” vs. “sensación de piezas distribuidas sobre cuadrados blancos y negros”). Quizás si queremos entender cómo se siente desinstalar nuestra interfaz gráfica para la realidad deberíamos imaginar cómo sería percibir las capas intermedias de una red neuronal convolucional.
La forma más sencilla de poner en evidencia la interfaz gráfica es cerrar los ojos. A diferencia de las redes neuronales artificiales, nuestra corteza cerebral no necesita imágenes de entrada para activarse: siempre se encuentra activada. Es equivocado pensar el cerebro como una máquina que se enciende para un determinado propósito y luego se apaga hasta la próxima vez que sea necesaria. Incluso durante las fases más profundas del sueño o bajo anestesia general, el cerebro muestra patrones complejos de activación que son similares a los observados durante la vigilia. Una forma de entender esta actividad constante es imaginar a un jugador de tenis esperando el saque de su rival: jamás observamos al jugador quieto, en una posición relajada y displicente; por el contrario, siempre lo vemos moverse en un intento de anticipar a su rival. El cerebro funciona de forma similar, siempre intentando anticipar las demandas y los desafíos de su entorno. La actividad espontánea que recorre el cerebro cuando no estamos haciendo nada (al menos en apariencia) no es aleatoria, sino que refleja los patrones de actividad observados durante la ejecución de distintas tareas cognitivas. La hipótesis es que el cerebro siempre se mantiene cerca de un patrón de actividad que es significativo para su supervivencia, lo cual debe representar una enorme ventaja evolutiva, ya que el consumo energético de la actividad espontánea del cerebro es casi el 20% de la energía total consumida por el cuerpo humano.El incremento del consumo energético cuando realizamos una tarea cognitiva es prácticamente despreciable. La gran mayoría del metabolismo cerebral está destinado a mantener la actividad espontánea que ocurre durante el estado basal.
Si una tormenta de actividad eléctrica visita constantemente nuestro cerebro, entonces, ¿por qué no vemos signos de esta actividad cuando cerramos los ojos? Cerrar los ojos no reemplaza una escena visual por otra, sino que elimina casi por completo el contenido de nuestra percepción visual. Pero incluso con los ojos cerrados, alguien con acceso a registros de la actividad neuronal de nuestro cerebro (por ejemplo, registros de fMRI) podría concluir equivocadamente que estamos percibiendo un montón de cosas, porque encontraría varias regiones visuales considerablemente activadas. ¿Qué está pasando? ¿Qué tiene de diferente la actividad cerebral causada por estímulos visuales de aquella actividad espontánea, como para que una resulte en percepción visual mientras que la otra no?
No tenemos una respuesta exacta a estas preguntas, pero sí varias hipótesis y especulaciones. Una de ellas es que no vemos la actividad espontánea de nuestro cerebro cuando cerramos los ojos porque en ese momento se inician procesos que señalan su irrelevancia e inhiben su acceso al espacio global de trabajo. Esto tiene pleno sentido desde la perspectiva evolutiva: si al cerrar los ojos nos invadieran complejos patrones visuales, podríamos tener problemas para distinguir lo real de lo alucinado, y hasta podríamos actuar con nuestros ojos cerrados como si en realidad estuviesen abiertos. Esta es una característica de nuestra interfaz gráfica para la realidad: nuestra conciencia se encuentra aislada de los distintos procesos neuronales que se manifiestan constantemente en nuestro cerebro, así como un usuario de Windows no tiene acceso a las rutinas del sistema operativo, sino únicamente a las aplicaciones gráficas con las que interactúa en la pantalla. Cuando cerramos los ojos, no queda nada en la percepción visual que se considere relevante para la conciencia y, por lo tanto, la interfaz nos presenta una escena vacía. Todo aquello que está asociado con procesos homeostáticos y autonómicos se desvanece porque es de escaso interés para nuestra conciencia. El cerebro puede encargarse de sí mismo, de la misma forma en que un sistema operativo se encarga de sí mismo; no es problema nuestro ocuparnos de su mantenimiento.
Tenemos algunas pistas sobre cuáles podrían ser los procesos neuronales que señalan la irrelevancia de la actividad neuronal presente al tener los ojos cerrados. El ritmo cerebral dominante en el electroencefalograma de una persona relajada y con los ojos cerrados oscila unas diez veces por segundo y es conocido como ritmo alfa. Cuando abrimos los ojos, el ritmo alfa desaparece casi por completo, y lo mismo sucede cuando nos involucramos activamente en distintas tareas cognitivas. En mi doctorado hice experimentos que combinaban mediciones de electroencefalografía y fMRI para localizar el origen de distintos ritmos en el cerebro,La necesidad de combinar ambas técnicas de neuroimágenes tiene que ver con las limitaciones intrínsecas a cada una de ellas. La resolución temporal de fMRI es muy pobre, por lo tanto, no es capaz de detectar ritmos que oscilan varias veces por segundo, tales como el ritmo alfa. Por el otro lado, la electroencefalografía tiene una resolución espacial muy pobre, por lo que es insuficiente para averiguar dónde en el cerebro se originan estos ritmos. La combinación de ambas técnicas permite identificar los ritmos y, además, localizarlos anatómicamente en el cerebro. y encontré que el ritmo alfa está inversamente correlacionado con la actividad y conectividad cerebral en regiones frontales y parietales del cerebro, regiones fundamentales para mantener y dirigir la atención. Esto apoya la hipótesis de que el ritmo alfa inhibe la atención e impide que la actividad cerebral se amplifique hasta publicarse en el espacio global de trabajo.
El ritmo alfa podría ser un indicador biológico de que nuestra interfaz gráfica está creando un compartimiento entre conciencia y cerebro.El ritmo alfa también desaparece durante el sueño REM. Si hubiese una forma de desactivar el ritmo alfa, quizás podríamos esperar que ciertos procesos cerebrales usualmente invisibles para la conciencia se manifiesten de repente, así como a veces la interfaz gráfica de Windows trastabilla y nos muestra pantallas negras o azules repletas de símbolos y códigos. ¿Existe una forma de desinstalar esta interfaz gráfica de la realidad, aunque sea por unos momentos? Y si fuese posible, ¿cómo se sentiría hacerlo?
El río Vaupés delimita una porción de la frontera entre Colombia y Brasil, para luego atravesar el estado brasileño de Amazonas hacia el sur y desembocar en el río Negro. Las aguas oscuras –por tramos navegables– están rodeadas por una densa vegetación que esconde las orillas. En esta cálida selva habitan los tucanos: aproximadamente 7000 descendientes de quienes, según su mito fundacional, arribaron a la región sobre una inmensa anaconda con forma de canoa.
Los tucanos son una de las muchas etnias nativas del Amazonas que utilizan la ayahuasca con fines religiosos y ceremoniales. Este uso fue documentado, entre otros, por el antropólogo austríaco Gerardo Reichel-Dolmatoff. Escapando de los horrores del Tercer Reich, Reichel-Dolmatoff llegó en 1939 a Bogotá y durante las décadas siguientes realizó investigaciones pioneras sobre las comunidades nativas de todo el territorio colombiano, desde las costas del Caribe hasta los Andes y las selvas del Amazonas. En sus últimos años, se interesó especialmente por el estado psicodélico inducido por la ayahuasca, e investigó tanto su uso ritual como sus profundos efectos sobre la conciencia y la relación de estos con el arte y la cosmología de los tucanos. En su libro El chamán y el jaguar, Reichel-Dolmatoff describió extensamente la relación entre la cultura de los tucanos y los estados de conciencia inducidos farmacológicamente, con énfasis en la experiencia causada por la ingesta de la ayahuasca. Entre sus muchas observaciones, se destacan aquellas sobre la forma en que los tucanos experimentan e interpretan los cambios visuales inducidos por la droga.
Reichel-Dolmatoff cuenta cómo el escaso interés de los tucanos por dibujar plantas o animales con crayones se transforma de inmediato en fascinación cuando la consigna es capturar las imágenes vistas durante la experiencia con ayahuasca, conocidas en el lenguaje de los tucanos como Gahpí ohori. Cuando uno de ellos comienza a dibujar, otros reconocen la naturaleza de los dibujos y se acercan, curiosos. De repente, todos quieren dibujar Gahpí ohori. Algunos fabrican herramientas improvisadas para poder dibujar figuras geométricas, como círculos y líneas rectas; otros hacen dibujos en la tierra para luego copiarlos en papel con crayón. Reichel-Dolmatoff clasifica los dibujos en dos categorías principales: algunos de ellos son puramente geométricos, mientras que otros son figurativos, aunque ocasionalmente también incluyen elementos abstractos. Los tucanos parecen estar familiarizados con estos dibujos casi de la misma forma en que nosotros reconocemos las letras del alfabeto. “Ese es vahsú, la Anaconda-Canoa”, dice uno de ellos, señalando varias curvas horizontales ondulantes y coloridas. Reichel-Dolmatoff descubre que todos los presentes parecen reconocer los dibujos, incluso aquellos más geométricos y sencillos; algunos hasta dicen ser capaces de estimar cuánta ayahuasca fue consumida a partir de sus formas.
La fascinación de los tucanos por sus Gahpí ohori es entendible. El Amazonas colombiano es una región donde todo es orgánico y lleno de vida. Es una tierra húmeda cubierta por plantas y árboles con enormes hojas verdes irregulares, piedras y cantos redondeados por las interminables lluvias estacionales, animales con pelos, plumas y escamas coloridas, noches cerradas y días oscuros, con el sol parcialmente ocluido por el follaje de la selva y por el vapor de agua en el aire. Esta tierra está muy lejos de los orígenes de la geometría abstracta en la Grecia antigua. Rara vez los tucanos posan sus ojos sobre objetos geométricos como círculos, cruces y triángulos; su experiencia cotidiana abunda en objetos irregulares como hojas, ramas y raíces. Pero un día, luego de beber una cocción hecha con grandes lianas y modestas hojas verdes, logran acceder de inmediato a un conocimiento que a los griegos les demandó décadas de abstracción. Cuando los tucanos descubren la ayahuasca, encuentran por primera vez a sus preciados Gahpí ohori. Con los ojos cerrados, observan un entramado de figuras geométricas coloridas, perfectas en cada uno de sus ángulos y contornos, figuras como nunca antes habían encontrado en la selva. Con los ojos entrecerrados, la selva se parece a un hermoso vitral de colores verdes y marrones, con patrones geométricos superpuestos sobre la belleza orgánica del mundo vivo al que están acostumbrados.
Los colores se multiplican y se vuelven más vívidos. En medio de la noche, los tucanos beben más ayahuasca y entran en una comunión extática con la selva y sus animales, reales y figurados. Por sobre todos ellos, reconocen a la inmensa anaconda que los trajo al Amazonas en tiempos ancestrales. En otros Gahpí ohori encuentran úteros, vaginas, semen, galaxias, estrellas, vegetales, sillas de madera y pensamientos. Los dibujan en alegría y en comunión, tan entusiasmados como niños que recién aprenden a ver el mundo:
FIG. 10.4 GAHPÍ OHORI
Podemos comparar cada uno de estos patrones con los que dibujaron los primeros marcianos operando bajo su interfaz gráfica para la realidad. Cada Gahpí ohori se encuentra en correspondencia aproximada con uno de los dibujos marcianos; quien lee puede hacer el ejercicio de identificar estas correspondencias comparando ambas figuras.Contando desde la esquina superior izquierda: el primero con el sexto, el segundo con el décimo, el tercero con el segundo, el cuarto con el séptimo, el quinto con el tercero, el sexto con el décimo (rotado a 90°), el séptimo con el cuarto, el octavo con el octavo, el noveno con una superposición del segundo, sexto y noveno, y el décimo con el quinto.
En realidad, tanto los Gahpí ohori como los dibujos marcianos son mi reproducción de una figura mostrada por Reichel-Dolmatoff en el capítulo 8 de El chamán y el jaguar. Lo que presenté como el resultado de la imaginación marciana son dibujos de fosfenos: patrones visuales resultantes de la excitación directa del nervio visual. El ingeniero alemán Max Knoll aplicó corrientes eléctricas al cuero cabelludo de más de 1000 voluntarios, quienes plasmaron sus experiencias de fosfenos en dibujos. Reichel-Dolmatoff reprodujo algunos de ellos en su libro para compararlos directamente con los dibujos hechos por los tucanos, encontrando similitudes (como las que describí en la última nota a pie de página). Su conclusión fue que el origen de los Gahpí ohori es entóptico; es decir, está causado por la percepción de actividad originada internamente en la corteza visual. En otras palabras, la ayahuasca permite que la actividad espontánea del cerebro ingrese a la conciencia. Tanto los dibujos hechos por los tucanos como por los marcianos surgen de un desplazamiento entre modos de conciencia, de apagar y encender la interfaz gráfica para la realidad.
Esta es una hipótesis consistente con todo lo que sabemos sobre la acción de los psicodélicos (incluyendo la ayahuasca) en el cerebro humano. Uno de los efectos más marcados y reproducibles asociados a los psicodélicos es la supresión casi total del ritmo alfa, incluso en un estado de reposo con los ojos cerrados. Esta pérdida del ritmo alfa fue documentada para ayahuasca, LSD, psilocibina, y DMT; en este último caso gracias a experimentos realizados por nuestro laboratorio. En un trabajo épico liderado por Carla Pallavicini, viajamos durante un año por el conurbano bonaerense registrando la actividad cerebral de decenas de individuos bajo los efectos de la DMT. Encontramos una supresión casi total del ritmo alfa durante los primeros diez minutos de cada experiencia, y luego un gradual regreso al estado basal que correlaciona con la recuperación de la vigilia ordinaria. Incluso con los ojos cerrados,Los ojos de los sujetos, no los nuestros. observamos señales de electroencefalografía prácticamente indistinguibles de aquellas medidas con los ojos abiertos. Concluimos que nuestros participantes estaban, literalmente, viendo con los ojos cerrados. Sus reportes nos lo confirmaron. Una tormenta constante de actividad neuronal apareció de repente en sus conciencias. Para algunos fue abrumador: una participante nos dijo que su experiencia visual fue tan intensa que sintió que tenía que abrir sus ojos para poder dejar de ver.
Si la supresión del ritmo alfa causada por los psicodélicos permite visualizar los patrones de actividad cerebral espontánea, entonces, ¿por qué esos patrones se ven de la forma en que se ven? ¿Por qué figuras geométricas y, en dosis más elevadas, fragmentos de imágenes, caras, ojos, formas de animales o plantas? ¿Por qué colores tan intensos? No conocemos aún la respuesta definitiva a estas preguntas, aunque (como siempre) disponemos de una hipótesis muy interesante.
Recordemos cómo las redes neuronales convolucionales procesan la información visual. Cada una de las capas representa información más y más compleja sobre la imagen. En las primeras etapas, encontramos detección de bordes y contornos; luego, fragmentos más complejos formados por la conjunción de segmentos orientados; finalmente, encontramos partes aisladas de objetos identificados por la red neuronal. En el caso de caras, por ejemplo, encontramos bocas, narices y ojos. Imaginemos una red convolucional activada de forma espontánea, de la misma forma en que observamos activaciones espontáneas en nuestra corteza visual. Imaginemos, además, que observamos las representaciones en las capas intermedias en vez del resultado final. Si esta actividad no se suprime y logra ingresar al espacio global de trabajo, esperamos ver caleidoscopios de figuras geométricas intercaladas con fragmentos de imágenes de distinta complejidad, dependiendo de la capa de la red que estamos visualizando. Los ingenieros de Google construyeron una demostración práctica de este fenómeno,https://deepdreamgenerator.com desarrollando un algoritmo que modifica imágenes hasta resaltar exageradamente los patrones detectados por una red neuronal. Las imágenes resultantes son decididamente psicodélicas; además, al modificar selectivamente distintas capas de la red se pueden simular distorsiones menos o más profundas.
FIG. 10.5 EL SUEÑO PSICODÉLICO DE UNA RED CONVOLUCIONAL
La forma de los patrones geométricos visibles con los ojos cerrados puede explicarse por la geometría misma de la corteza visual. Reichel-Dolmatoff no fue la primera persona en registrar patrones geométricos reportados repetidamente durante el estado psicodélico. En el año 1926, Heinrich Klüver investigó sistemáticamente la forma de las distorsiones visuales producidas por la ingesta de mescalina y encontró que los reportes de sus sujetos podían ser clasificados en categorías que denominó constantes de forma. Las constantes de forma identificadas por Klüver son las siguientes: retículos (incluyendo cuadriculados o hexagonales tipo panal de abejas), telas de araña, túneles y espirales. También observó que estas constantes de forma aparecían bajo otras condiciones, como durante migrañas, ataques de epilepsia, estimulación con luces, estimulación eléctrica, y hasta presionando los ojos para producir fosfenos. La ubicuidad de estos patrones hizo a Klüver sospechar que podría haber un factor común a todas estas experiencias.
Pero ¿qué tienen en común los efectos de la mescalina con una migraña o con un ataque de epilepsia? Klüver nunca podría haberlo adivinado: todavía faltaban algunas décadas para que Hubel y Wiesel revelasen la estructura de la corteza visual primaria. Este descubrimiento renovó el interés de la comunidad neurocientífica en las constantes de forma y atrajo la atención de Jack Cowan, uno de los teóricos más prominentes de la época. Cowan se planteó la siguiente pregunta: si conocemos la forma en que están dispuestas las neuronas de la corteza visual primaria y, además, suponemos que esas neuronas se excitan espontáneamente de forma aleatoria, ¿podemos predecir cómo se percibirían esos patrones de activación? Usualmente no habría percepción alguna debido a la inhibición que impide el acceso al espacio global de trabajo. Pero si esta inhibición no estuviese y pudiésemos experimentar esta actividad como un estímulo visual, ¿podríamos aprender algo sobre la estructura de la corteza visual durante la experiencia?
A diferencia de Klüver, Cowan estaba al tanto de los experimentos de Hubel y Wiesel y, por lo tanto, sabía que las neuronas de la corteza visual primaria se encuentran agrupadas en columnas perpendiculares a la superficie cortical. Estas estructuras se repiten de forma periódica, como los cuadrados sobre un tablero de ajedrez y los hexágonos en un panal de abejas. Y esta estructura regular sería la explicación de por qué las distorsiones inducidas por psicodélicos también son regulares y obedecen a los principios geométricos que se desprenden de la organización columnar de la corteza cerebral, incluso en aquellos lugares del mundo donde los habitantes ignoran por completo los conceptos de geometría plana que nosotros aprendimos en la escuela. Cowan demostró que excitar neuronas aleatoriamente en esta red regular resulta en las constantes de forma documentadas por Klüver. Son dos caras de la misma moneda: el carácter geométrico de las distorsiones visuales refleja cómo están organizadas las columnas de la corteza visual primaria. Todos disponemos de esta organización y, por lo tanto, todos vemos las mismas constantes de forma, desde los tucanos investigados por Reichel-Dolmatoff hasta un oficinista que se refriega la cara por la tarde, cansado, y sin querer se aprieta el globo ocular con un dedo.
Esto parece contradecir una de las primeras afirmaciones que hicimos en el libro. Dijimos que la percepción y la introspección están irremediablemente disociadas, de forma tal que no podemos examinar la naturaleza de nuestras experiencias conscientes para revelar información sobre la estructura física del cerebro. Pero esto es lo que son las constantes de forma: ecos de la arquitectura cerebral en la percepción visual consciente. Podemos utilizar métodos de neuroimágenes (por ejemplo, fMRI) para examinar en tercera persona los patrones de actividad neuronal espontánea en las regiones visuales del cerebro. Pero los psicodélicos también nos permiten examinar esos patrones en primera persona, y, por lo tanto, podemos decir que son métodos de autoneuroimágenes. Lo que las autoneuroimágenes nos muestran está más allá del velo de apariencias que extiende la interfaz gráfica. Una disfunción inesperada de un sistema operativo puede mostrarnos pantallas azules repletas de símbolos que representan los procesos ocultos detrás de íconos y ventanas. De la misma manera, una disfunción en nuestro cerebro puede mostrarnos constantes de forma que representan procesos ocultos detrás de nuestras sensaciones subjetivas usuales. En ambos casos, experimentamos en primera persona procesos que se desenvuelven en un nivel inferior, usualmente oculto: levantamos el capot, desarmamos el gabinete, descendemos bajo cubierta, espiamos tras bambalinas, entramos en la cocina, miramos los planos, miramos hacia adentro, miramos el cerebro.
Es difícil intentar explicar la conciencia sin explorar otras formas de conciencia diferentes a la usual. ¿Cómo podríamos explicar el funcionamiento del microprocesador de una computadora únicamente a partir de las cosas que vemos en el monitor? Si nuestro acceso está limitado a íconos, ventanas y aplicaciones, entonces podría parecer que el objetivo es inalcanzable. Pero si logramos escapar de esta presentación simplificada para indagar en el código legible por el procesador, entonces podremos aprender un montón de cosas que antes nos estaban irremediablemente vedadas. Sucede lo mismo con nuestra conciencia, solo que en este caso únicamente tenemos intuiciones muy incompletas sobre cómo escapar de la interfaz gráfica.
Los pesimistas sostienen que el problema de la conciencia es imposible de resolver porque hay una brecha insalvable entre la naturaleza de las experiencias subjetivas y las explicaciones que formulamos en términos científicos. ¿Cómo sería posible explicar en términos de la física, la química y la biología cosas como la sensación del color rojo o un desagradable dolor de muelas? Es verdad que la explicación de la conciencia parece imposible desde donde estamos parados en el día a día. Pero, como aprendimos jugando a ser naturalistas del siglo XIX, no tenemos por qué quedarnos siempre en el mismo lugar si queremos entender la naturaleza. Quizás cambiando la experiencia subjetiva podamos acceder a estados de conciencia donde la brecha se haga más angosta, donde las sensaciones de rojo y dolor ya no se encuentren completamente encapsuladas por fuera de sus sustratos neuronales y sus roles funcionales, así como las constantes de forma de Klüver y los Gahpí ohori documentados por Reichel-Dolmatoff no son solamente experiencias conscientes sobre líneas, círculos, triángulos y entramados, sino también sobre la forma en que nuestras cortezas visuales están parceladas en columnas de neuronas sensibles a distintas orientaciones en el espacio.
Un escéptico debe siempre insistir en el siguiente punto: incluso si nuestras experiencias conscientes revelasen cada detalle del procesamiento neuronal subyacente, seguirían siendo experiencias conscientes, y, por lo tanto, seguiría existiendo una brecha insalvable. Este escepticismo tiene mucho que ver con ciertas propiedades únicas que parecen tener los qualia. Por ejemplo, parece imposible describir la sensación de color rojo (u otros qualia) mediante palabras. ¿Cómo podríamos desarrollar una explicación científica de algo que ni siquiera podemos describir usando el lenguaje?
Esta es la misma pregunta que podría hacerse un programador que trata de entender cómo el código de computadora da origen a los íconos y ventanas de la interfaz gráfica. Las imágenes que nos presenta un sistema operativo como Windows simplifican tanto nuestra tarea que podemos caer en el error de creer que ellas mismas son simples. La generación de estas imágenes puede explicarse analizando código, pero este código tiene muy poco que ver, a primera vista, con la imagen en sí misma. Podemos verificarlo abriendo un archivo de imagen (por ejemplo, en formato .png) con el bloc de notas en vez de con Paint u otro programa para visualizar gráficos. Encontraremos algo parecido a esto en el cuerpo del archivo:
Estos caracteres no tienen sentido para nosotros, pero eso es lógico, porque no están destinados a nosotros, sino a la computadora. Interpretados como código de máquina, son idénticos a la imagen en cuestión: no hay nada presente en la imagen que no se encuentre en el código y viceversa.
Es posible aprender las reglas de esta codificación mediante un ejercicio de ingeniería inversa. Un primer paso razonable consiste en obtener la representación de dos imágenes formadas por un único píxel, en un caso encendido, y en el otro apagado:
Las diferencias entre estas dos cadenas de caracteres (indicadas con itálicas) deben estar relacionadas con encender un píxel. Luego podemos estudiar todas las imágenes con 2 x 2 píxeles, 3 x 3 píxeles, y así sucesivamente. Con el tiempo, descubriremos una sintaxis y, si practicamos mucho, puede que algún día seamos capaces de escribir imágenes sin siquiera tener que dibujarlas antes. No hay nada sobre la imagen que no podamos transmitir mediante caracteres, aunque hacerlo es difícil y depende de reglas muy complicadas. Si sentimos que la información presente en la imagen trasciende cualquier descripción lingüística, es simplemente porque esta descripción es demasiado complicada como para imaginarla y tenerla presente cada vez que interactuamos con la imagen.
Esta analogía sirve para mostrar por qué los qualia parecen trascender el lenguaje. En realidad, no hay nada sobre ellos que no podamos expresar mediante una producción lingüística adecuada. El problema es que esta expresión es demasiado compleja para ser siquiera imaginada por un ser humano. Tendemos a imaginar descripciones de sensaciones subjetivas basadas en nuestro lenguaje cotidiano, para luego hacerlas cada vez más completas y exhaustivas, y finalmente concluir que siempre algo quedará por fuera de estas descripciones. Pero tal como para una computadora, estas expresiones no existen para que las entiendan los humanos; en el caso de la conciencia, hacen referencia a neuronas y sus conexiones y activaciones. La inefabilidad de los qualia es una ilusión causada por la inmensa complejidad del lenguaje que precisaríamos para comunicarlos. Una buena noticia es que podemos intentar aproximarnos a expresar esta complejidad (como mostramos en el capítulo anterior) y hasta podemos experimentar cómo se sentiría poder hacerlo en primera persona (como mostramos en este).
Pero este argumento podría no convencer a todos los escépticos. Parece haber algo más presente cuando vemos un objeto rojo que cuando leemos una descripción exhaustiva de la sensación de color rojo en términos neurobiológicos. Más aún, esto que está presente existe únicamente para quien está viendo el objeto rojo y, por lo tanto, decimos que la conciencia es privada. Entonces, ¿no hay algo que trasciende cualquier explicación mediante el lenguaje? ¿Y ese algo no es únicamente conocido por la persona que tiene esa experiencia?
Puede que sí, aunque estas no son las preguntas que deberíamos hacernos. Seguro no es lo mismo explicar un fenómeno que el fenómeno mismo y seguro cada instancia del fenómeno tiene propiedades por las cuales es diferente a los demás. Pero esto es así para cualquier fenómeno, no solo para la conciencia. La ley de Newton no es la gravedad: aunque pueda usarse para explicar y predecir movimientos bajo campos gravitatorios, la ley por sí misma no ejerce ninguna fuerza gravitatoria y tampoco actúan fuerzas sobre ella. Y aunque tanto Júpiter como Venus tengan campos gravitatorios que se rigen por la misma ley, estos campos gravitatorios no son idénticos: uno pertenece a Júpiter y el otro, a Venus.
La pregunta que sí deberíamos hacernos es: ¿hay algo único y especial sobre la conciencia que obstaculice su explicación científica? Filósofos como Daniel Dennett y Keith Frankish han argumentado durante décadas que las propiedades problemáticas de los qualia (tales como inefabilidad y privacidad) son ilusorias. Estas ilusiones hacen que nuestra interfaz gráfica para la realidad funcione y, por lo tanto, es muy difícil desprendernos de ellas. Incluso recalibrar nuestras intuiciones es complicado: requiere pensar más allá de la interfaz y sus contenidos, como en un párrafo anterior, cuando tratamos de entender por qué no hay nada inefable sobre la experiencia subjetiva. Investigar estados de conciencia donde estas ilusiones parecen disiparse es uno de los mejores antídotos contra el pesimismo injustificado en cuanto a una posible explicación científica de la conciencia.
Pero los escépticos tienen una última objeción para ofrecernos: incluso si es verdad que los qualia no poseen misteriosas propiedades inexplicables para la ciencia, sigue habiendo un problema, porque la ilusión se desarrolla dentro de nuestra conciencia. Aunque no tenga las propiedades que parece tener, ¿por qué tenemos siquiera algún tipo de experiencia consciente en primer lugar? ¿Y por qué es tan diferente la conciencia del resto de las propiedades de la materia? El problema de estas preguntas es que ya presuponen su respuesta, es decir, asumen que existe una brecha insalvable entre mente y materia. Pero nunca logramos desinstalar nuestra interfaz gráfica, así que no sabemos cómo sería tener experiencias conscientes sin qualia. En particular, no sabemos si la brecha explicativa permanecería. No es obvio que al disipar la ilusión de los qualia el remanente siga siendo problemático: no podemos afirmar que no sea el caso porque nadie nunca lo ha experimentado, pero tampoco podemos afirmar que sí sea el caso, precisamente por el mismo motivo.
Es interesante notar que ni siquiera es necesario alcanzar un estado de conciencia sin qualia para convencernos de que la conciencia es explicable en términos científicos. El problema de la conciencia-F es su aparente disociación total respecto de las funciones cognitivas; es decir, el hecho de que la conciencia-F parece ser optativa para absolutamente todos nuestros comportamientos. Y si los comportamientos son lo que podemos medir en el laboratorio, entonces, ¿cómo podrían informarnos acerca de la conciencia-F? Pero quizás no sea el caso. Quizás únicamente parezca que es el caso. En su trabajo sobre el metaproblema de la conciencia, David Chalmers sugiere que el problema difícil de la conciencia podría desaparecer si pudiéramos demostrar que
hay conciencia-F, pero solo en el sentido según el cual la conciencia-F se entiende funcionalmente; por ejemplo, la conciencia-F podría ser entendida como aquello que causa nuestros reportes sobre la conciencia. El problema difícil se fundamenta en la afirmación de que la conciencia-F no es un concepto funcional, es decir, no es un concepto sobre causar ciertos comportamientos y otras consecuencias cognitivas. Esto es lo que genera una grieta entre explicar funciones del comportamiento y explicar la conciencia. Pero si la conciencia-F es un concepto funcional, entonces la grieta desaparece.
El estado psicodélico sugiere que es posible adquirir información directa sobre la estructura física del cerebro y su funcionamiento como parte de la experiencia consciente. Pero esa experiencia también tiene propiedades fenoménicas (qualia) como ser colores, formas, y texturas. Es difícil imaginar cómo podríamos tener experiencias informativas sobre el cerebro en completa ausencia de qualia. Pero esto no es necesario, argumenta Chalmers: solo necesitamos romper la disociación aparente entre qualia y función. Y es perfectamente imaginable conseguir esto mediante una modificación adecuada de la conciencia, tal como sugerimos en el presente capítulo.
Explorar diferentes estados de conciencia puede tener un rol transformativo respecto de nuestras intuiciones sobre el problema científico de la conciencia. Podemos dividir las cosas que suceden en nuestro cerebro en dos categorías: transparentes y opacas a la conciencia. Las transparentes son ubicuas, pero también invisibles, como el agua en la que nadan los peces. Las opacas son visibles y, por lo tanto, ingresan a nuestra experiencia consciente. Estas categorías se pueden reconfigurar, por ejemplo, mediante la inducción de estados alterados de conciencia. En particular, vimos cómo los psicodélicos hacen que algunos aspectos de la estructura física del cerebro se vuelvan opacos a la conciencia. Esto puede tener importantes implicaciones en el metaproblema de la conciencia (es decir, ¿por qué distintas personas poseen diferentes intuiciones sobre la dificultad del problema de la conciencia?). David Armstrong establece una comparación con la ilusión de la mujer sin cabeza. Si le pedimos a una mujer que se siente en una silla sobre un fondo negro y luego le tapamos la cabeza con un paño del mismo color, los observadores tendrán la impresión de que la mujer no tiene cabeza (algunos hasta creerán que efectivamente no la tiene). Esto muestra la facilidad con la que los humanos saltamos desde “no percibo que la mujer tenga cabeza” a “percibo que la mujer no tiene cabeza”. Análogamente, argumenta Armstrong, saltamos de “mi introspección no muestra que mi conciencia tenga un origen físico” a “mi introspección muestra que mi conciencia no tiene un origen físico”. Como en el caso de la mujer sin cabeza, el salto de una afirmación a la otra no parece tener un sustento real. Quizás ciertos estados alterados de conciencia, como el inducido por psicodélicos, puedan socavar nuestra tendencia a realizar la primera afirmación, eliminando entonces el salto hacia la segunda afirmación.
Intentemos imaginar cómo la interfaz gráfica para la realidad se desvanece gradualmente, dejando únicamente en nuestra experiencia consciente contenidos que identificamos y entendemos a partir de su función, y cómo esta función está implementada en los circuitos neuronales del cerebro. La brecha entre mente y materia se hace cada vez más pequeña, y nuestras explicaciones sobre el sustrato neuronal de la conciencia se vuelven cada vez más transparentes. Hasta que en un punto final –quizás inalcanzable, pero aproximable– la brecha desaparece, y con ella, la distinción entre lo físico y lo mental, entre el interior y el exterior. Ya no hay paredes invisibles que angosten nuestro recorrido por el laberinto.
Para evitar que Teseo se pierda irremediablemente en su recorrido por el laberinto del Minotauro, Ariadna le regaló un hilo que servía para poder retroceder sobre sus pasos y desandar el camino. El nudo en el hilo es idéntico al laberinto: es aquello que debemos deshacer para encontrar la salida.
¿De qué está hecha la experiencia? ¿En qué lugar de nuestro cerebro reside el sabor de una comida o el sonido de nuestra canción favorita? Un tratado que condensa una década de investigación original del Dr. Enzo Tagliazucchi, y discute las concepciones históricas y contemporáneas sobre la conciencia humana, uno de los enigmas más insondables para la humanidad.
464 páginas, con gráficos a color. Ganador del Sello Buen Diseño.
El nudo de la conciencia$36.500
¿De qué está hecha la experiencia? ¿En qué lugar de nuestro cerebro reside el sabor de una comida o el sonido de nuestra canción favorita? Un tratado que condensa una década de investigación original del Dr. Enzo Tagliazucchi, y discute las concepciones históricas y contemporáneas sobre la conciencia humana, uno de los enigmas más insondables para la humanidad.
464 páginas, con gráficos a color. Ganador del Sello Buen Diseño.
El nudo de la conciencia Ebook$12.500
¿De qué está hecha la experiencia? ¿En qué lugar de nuestro cerebro reside el sabor de una comida o el sonido de nuestra canción favorita? Un tratado que condensa una década de investigación original del Dr. Enzo Tagliazucchi, y discute las concepciones históricas y contemporáneas sobre la conciencia humana, uno de los enigmas más insondables para la humanidad.
Formato .epub
El nudo de la conciencia - edición especial$45.000
¿De qué está hecha la experiencia? ¿En qué lugar de nuestro cerebro reside el sabor de una comida o el sonido de nuestra canción favorita? Un tratado que condensa una década de investigación original del Dr. Enzo Tagliazucchi, y discute las concepciones históricas y contemporáneas sobre la conciencia humana, uno de los enigmas más insondables para la humanidad.
464 páginas, con gráficos a color. Edición especial con tapa dura.
Ciencia y diseño para entender el mundo como es, cómo podría ser y cómo queremos que sea.